- JavaScript SEO issues and best practices
- Have unique title tags and meta descriptions
- Canonical tag issues
- Google uses the most restrictive meta robots tag
- Set alt attributes on images
- Allow crawling of JavaScript files
- Check if Google sees your content
- Duplicate content issues
- Don’t use fragments (#) in URLs
- Create a sitemap
- Status codes and soft 404s
- JavaScript redirects are OK, but not preferred
- Internationalization issues
- Use structured data
- Use standard format links
- Use file versioning to solve for impossible states being indexed
- You may not see what is shown to Googlebot
- Use polyfills for unsupported features
- Use lazy loading
- Infinite scroll issues
- Performance issues
- JavaScript sites use more crawl budget
- Workers aren’t supported, or are they?
- Use HTTP connections
- JavaScript SEO testing tools and troubleshooting
- Google testing tools
- URL Inspection tool in Google Search Console
- Rich Results Test tool
- Mobile-Friendly Test tool
- Ahrefs
- View source vs. inspect
- Sometimes you need to check view source
- Don’t browse with JavaScript turned off
- Don’t use Google Cache
- How Google processes pages with JavaScript
- 1. Crawler
- 2. Processing
- Resources and links
- Caching
- Duplicate elimination
- Most restrictive directives
- 3. Render queue
- 4. Renderer
- Cached resources
- There’s no five-second timeout
- What Googlebot sees
- 5. Crawl queue
- JavaScript rendering options
- Final thoughts
Did you know that while the Ahrefs Blog is powered by WordPress, much of the rest of the site is powered by JavaScript like React?
The reality of the current web is that JavaScript is everywhere. Most websites use some kind of JavaScript to add interactivity and improve user experience.
Yet most of the JavaScript used on so many websites won’t impact SEO at all. If you have a normal WordPress install without a lot of customization, then likely none of the issues will apply to you.
Where you will run into issues is when JavaScript is used to build an entire page, add or take away elements, or change what was already on the page. Some sites use it for menus, pulling in products or prices, grabbing content from multiple sources or, in some cases, for everything on the site. If this sounds like your site, keep reading.
We’re seeing entire systems and apps built with JavaScript frameworks and even some traditional CMSes with a JavaScript flair where they’re headless or decoupled. The CMS is used as the backend source of data, but the frontend presentation is handled by JavaScript.
I’m not saying that SEOs need to go out and learn how to program JavaScript. I actually don’t recommend it because it’s not likely that you will ever touch the code. What SEOs need to know is how Google handles JavaScript and how to troubleshoot issues.
JavaScript SEO is a part of technical SEO (search engine optimization) that makes JavaScript-heavy websites easy to crawl and index, as well as search-friendly. The goal is to have these websites be found and rank higher in search engines.
JavaScript is not bad for SEO, and it’s not evil. It’s just different from what many SEOs are used to, and there’s a bit of a learning curve.
A lot of the processes are similar to things SEOs are already used to seeing, but there may be slight differences. You’re still going to be looking at mostly HTML code, not actually looking at JavaScript.
All the normal on-page SEO best practices still apply. See our guide on on-page SEO.
You’ll even find familiar plugin-type options to handle a lot of the basic SEO elements, if it’s not already built into the framework you’re using. For JavaScript frameworks, these are called modules, and you’ll find lots of package options to install them.
There are versions for many of the popular frameworks like React, Vue, Angular, and Svelte that you can find by searching for the framework + module name like React Helmet. Meta tags, Helmet, and Head are all popular modules with similar functionality and allow for many of the popular tags needed for SEO to be set.
In some ways, JavaScript is better than traditional HTML, such as ease of building and performance. In some ways, JavaScript is worse, such as it can’t be parsed progressively (like HTML and CSS can be), and it can be heavy on page load and performance. Often, you may be trading performance for functionality.
JavaScript isn’t perfect, and it isn’t always the right tool for the job. Developers do overuse it for things where there’s probably a better solution. But sometimes, you have to work with what you are given.
These are many of the common SEO issues you may run into when working with JavaScript sites.
You’re still going to want to have unique title tags and meta descriptions across your pages. Because a lot of the JavaScript frameworks are templatized, you can easily end up in a situation where the same title or meta description is used for all pages or a group of pages.
Check the Duplicates report in Ahrefs’ Site Audit and click into any of the groupings to see more data about the issues we found.
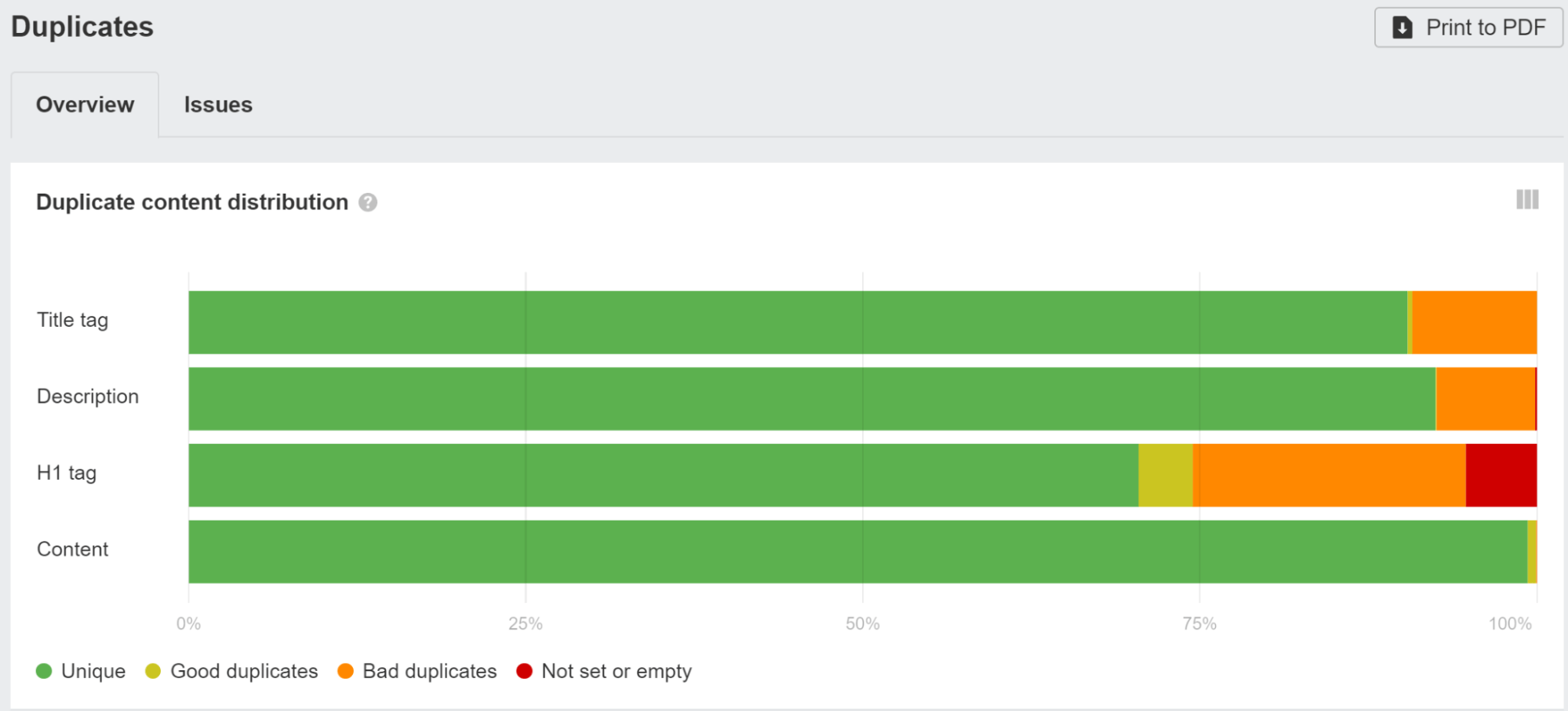
You can use one of the SEO modules like Helmet to set custom tags for each page.
JavaScript can also be used to overwrite default values you may have set. Google will process this and use the overwritten title or description. For users, however, titles can be problematic, as one title may appear in the browser and they’ll notice a flash when it gets overwritten.
If you see the title flashing, you can use Ahrefs’ SEO Toolbar to see both the raw HTML and rendered versions.
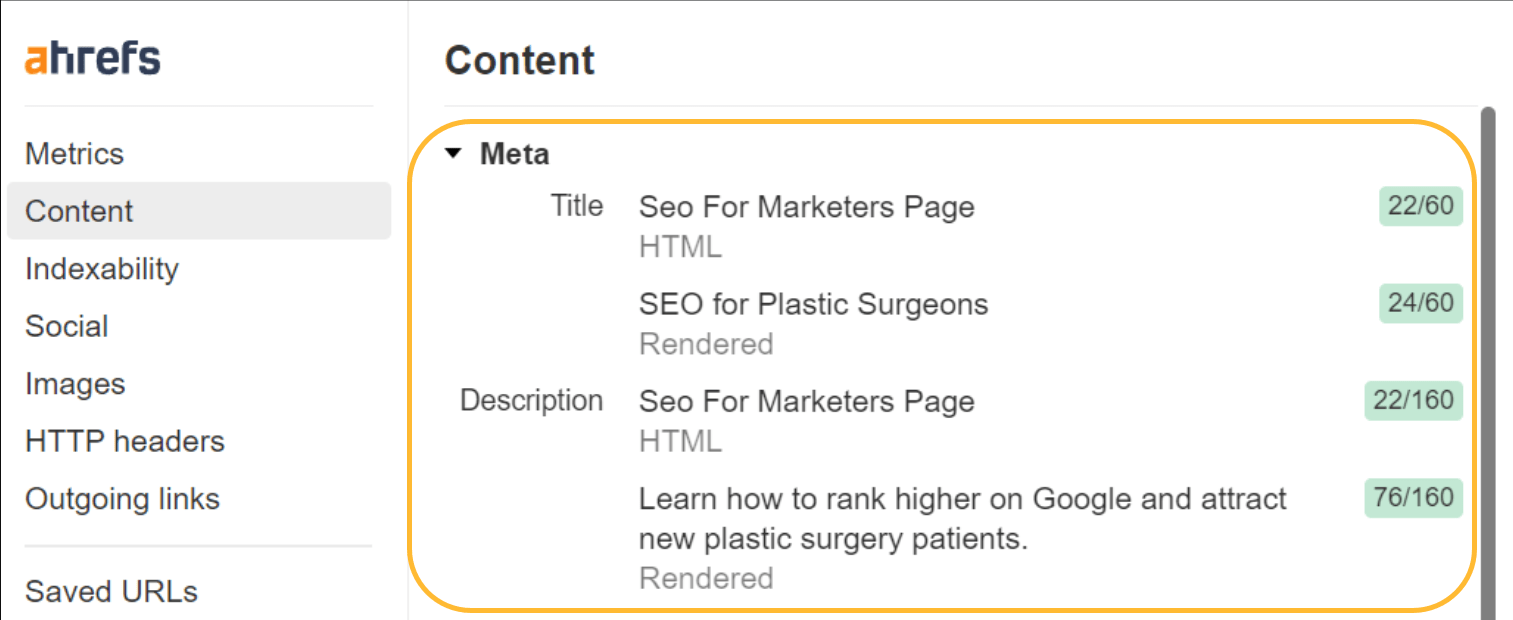
Google may not use your titles or meta descriptions anyway. As I mentioned, the titles are worth cleaning up for users. Fixing this for meta descriptions won’t really make a difference, though.
When we studied Google’s rewriting, we found that Google overwrites titles 33.4% of the time and meta descriptions 62.78% of the time. In Site Audit, we’ll even show you which of your title tags Google has changed.
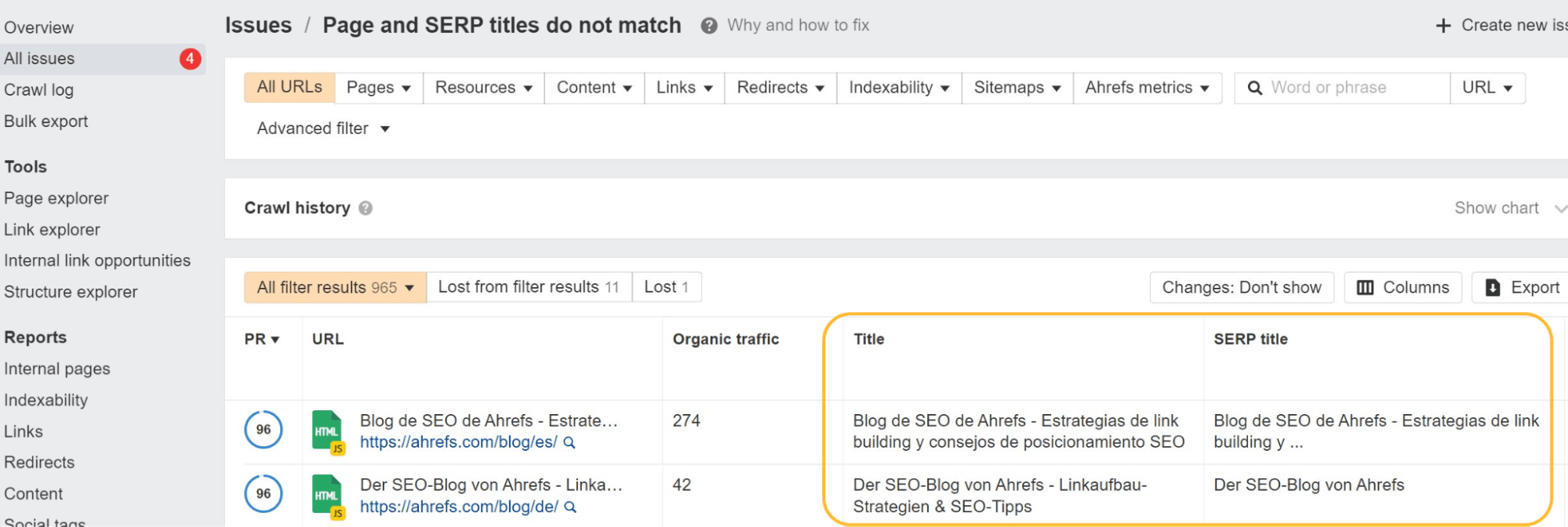
Canonical tag issues
For years, Google said it didn’t respect canonical tags inserted with JavaScript. It finally added an exception to the documentation for cases where there wasn’t already a tag. I caused that change. I ran tests to show this worked when Google was telling everyone it didn’t.
If there was already a canonical tag present and you add another one or overwrite the existing one with JavaScript, then you’re giving them two canonical tags. In this case, Google has to figure out which one to use or ignore the canonical tags in favor of other canonicalization signals.
Standard SEO advice of “every page should have a self-referencing canonical tag” gets many SEOs in trouble. A dev takes that requirement, and they make pages with and without a trailing slash self-canonical.
example.com/page with a canonical of example.com/page and example.com/page/ with a canonical of example.com/page/. Oops, that’s wrong! You probably want to redirect one of those versions to the other.
The same thing can happen with parameterized versions that you may want to combine, but each is self-referencing.
Google uses the most restrictive meta robots tag
With meta robots tags, Google is always going to take the most restrictive option it sees—no matter the location.
If you have an index tag in the raw HTML and noindex tag in the rendered HTML, Google will treat it as noindex. If you have a noindex tag in the raw HTML but you overwrite it with an index tag using JavaScript, it’s still going to treat that page as noindex.
It works the same for nofollow tags. Google is going to take the most restrictive option.
Set alt attributes on images
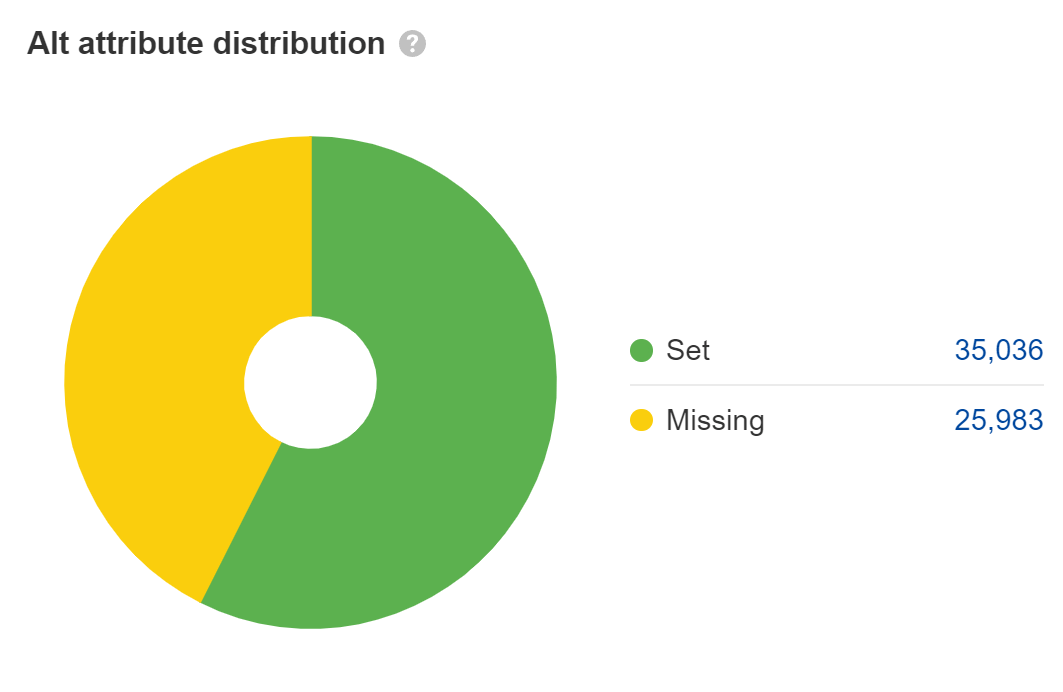
Missing alt attributes are an accessibility issue, which may turn into a legal issue. Most big companies have been sued for ADA compliance issues on their websites, and some get sued multiple times a year. I’d fix this for the main content images, but not for things like placeholder or decorative images where you can leave the alt attributes blank.
For web search, the text in alt attributes counts as text on the page, but that’s really the only role it plays. Its importance is often overstated for SEO, in my opinion. However, it does help with image search and image rankings.
Lots of JavaScript developers leave alt attributes blank, so double-check that yours are there. Look at the Images report in Site Audit to find these.
Allow crawling of JavaScript files
Don’t block access to resources if they are needed to build part of the page or add to the content. Google needs to access and download resources so that it can render the pages properly. In your robots.txt, the easiest way to allow the needed resources to be crawled is to add:
User-Agent: GooglebotAllow: .jsAllow: .css
Also check the robots.txt files for any subdomains or additional domains you may be making requests from, such as those for your API calls.
If you have blocked resources with robots.txt, you can check if it impacts the page content using the block options in the “Network” tab in Chrome Dev Tools. Select the file and block it, then reload the page to see if any changes were made.
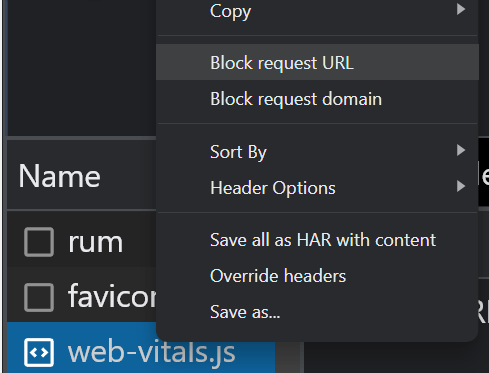
Check if Google sees your content
Many pages with JavaScript functionality may not be showing all of the content to Google by default. If you talk to your developers, they may refer to this as being not Document Object Model (DOM) loaded. This means the content wasn’t loaded by default and might be loaded later with an action like a click.
A quick check you can do is to simply search for a snippet of your content in Google inside quotation marks. Search for “some phrase from your content” and see if the page is returned in the search results. If it is, then your content was likely seen.
Sidenote.
Content that is hidden by default may not be shown within your snippet on the SERPs. It’s especially important to check your mobile version, as this is often stripped down for user experience.
You can also right-click and use the “Inspect” option. Search for the text within the “Elements” tab.
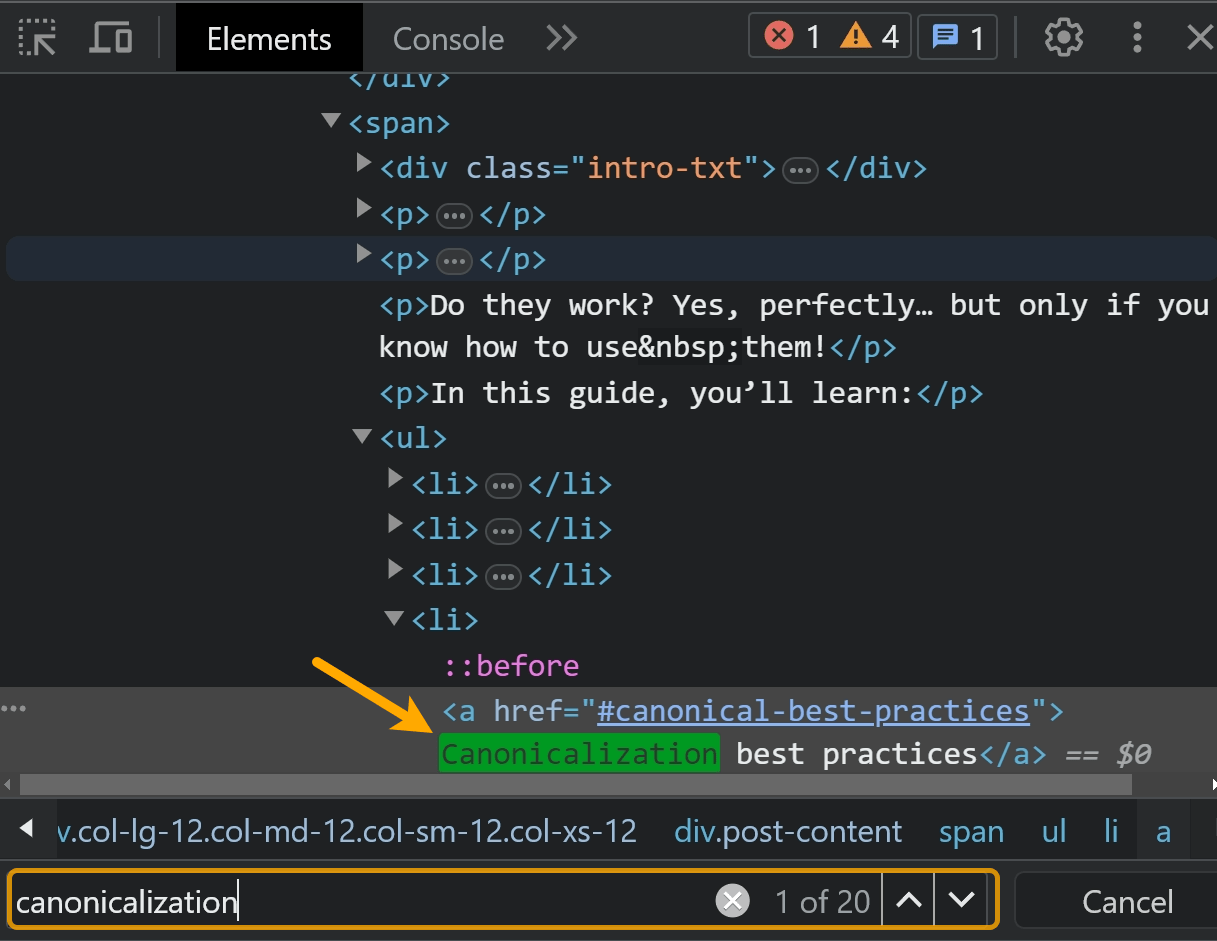
The best check is going to be searching within the content of one of Google’s testing tools like the URL Inspection tool in Google Search Console. I’ll talk more about this later.
I’d definitely check anything behind an accordion or a dropdown. Often, these elements make requests that load content into the page when they are clicked on. Google doesn’t click, so it doesn’t see the content.
If you use the inspect method to search content, make sure to copy the content and then reload the page or open it in an incognito window before searching.
If you’ve clicked the element and the content loaded in when that action was taken, you’ll find the content. You may not see the same result with a fresh load of the page.
Duplicate content issues
With JavaScript, there may be several URLs for the same content, which leads to duplicate content issues. This may be caused by capitalization, trailing slashes, IDs, parameters with IDs, etc. So all of these may exist:
domain.com/Abcdomain.com/abcdomain.com/123domain.com/?id=123
If you only want one version indexed, you should set a self-referencing canonical and either canonical tags from other versions that reference the main version or ideally redirect the other versions to the main version.
Check the Duplicates report in Site Audit. We break down which duplicate clusters have canonical tags set and which have issues.
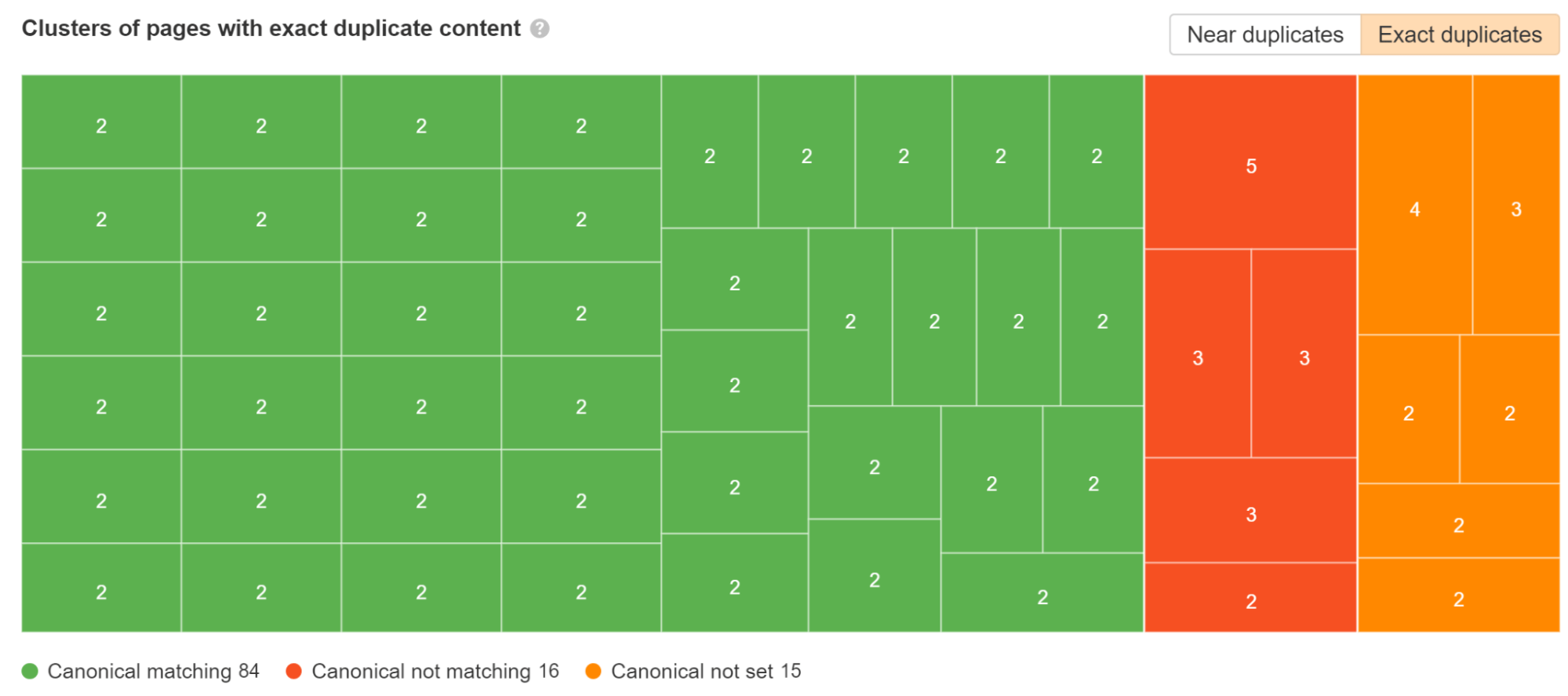
A common issue with JavaScript frameworks is that pages can exist with and without the trailing slash. Ideally, you’d pick the version you prefer and make sure that version has a self-referencing canonical tag and then redirect the other version to your preferred version.
With app shell models, very little content and code may be shown in the initial HTML response. In fact, every page on the site may display the same code, and this code may be the exact same as the code on some other websites.
If you see a lot of URLs with a low word count in Site Audit, it may indicate you have this issue.
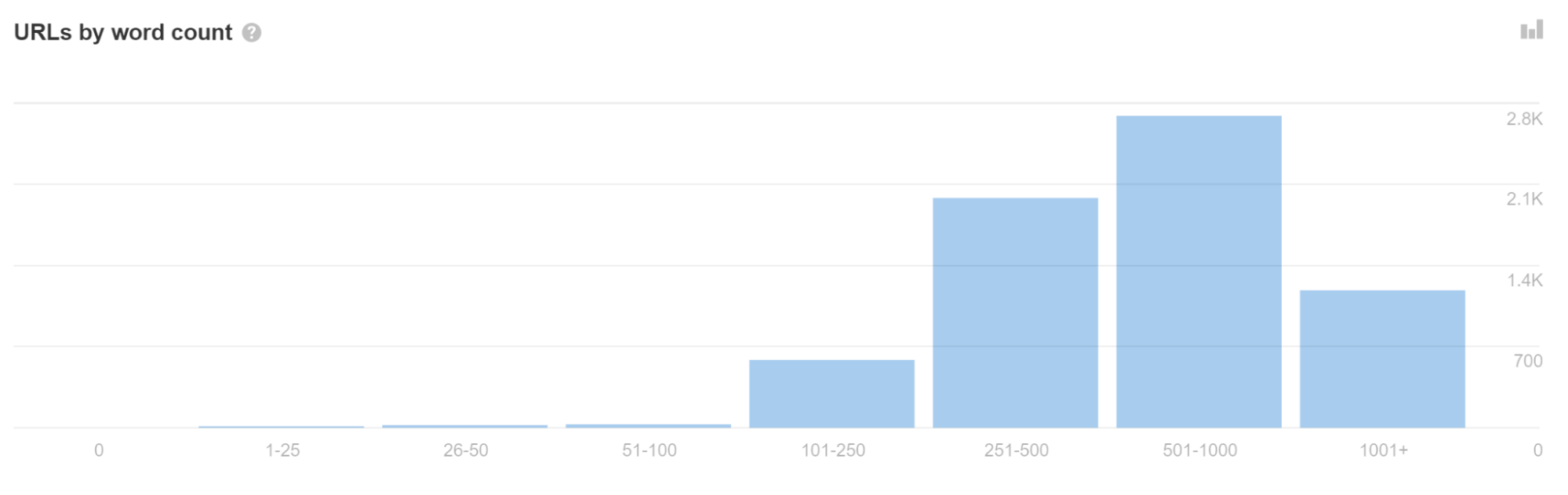
This can sometimes cause pages to be treated as duplicates and not immediately go to rendering. Even worse, the wrong page or even the wrong site may show in search results. This should resolve itself over time but can be problematic, especially with newer websites.
Don’t use fragments (#) in URLs
# already has a defined functionality for browsers. It links to another part of a page when clicked—like our “table of contents” feature on the blog. Servers generally won’t process anything after a #. So for a URL like abc.com/#something, anything after a # is typically ignored.
JavaScript developers have decided they want to use # as the trigger for different purposes, and that causes confusion. The most common ways they’re misused are for routing and for URL parameters. Yes, they work. No, you shouldn’t do it.
JavaScript frameworks typically have routers that map what they call routes (paths) to clean URLs. A lot of JavaScript developers use hashes (#) for routing. This is especially a problem for Vue and some of the earlier versions of Angular.
To fix this for Vue, you can work with your developer to change the following:
Vue router: Use ‘History’ Mode instead of the traditional ‘Hash’ Mode.
const router = new VueRouter ({mode: ‘history’,router: () //the array of router links)}
There’s a growing trend where people are using # instead of ? as the fragment identifier, especially for passive URL parameters like those used for tracking. I tend to recommend against it because of all of the confusion and issues. Situationally, I might be OK with it getting rid of a lot of unnecessary parameters.
Create a sitemap
The router options that allow for clean URLs usually have an additional module that can also create sitemaps. You can find them by searching for your system + router sitemap, such as Vue router sitemap.
Many of the rendering solutions may also have sitemap options. Again, just find the system you use and Google the system + sitemap such as Gatsby sitemap, and you’re sure to find a solution that already exists.
Status codes and soft 404s
Because JavaScript frameworks aren’t server-side, they can’t really throw a server error like a 404. You have a couple of different options for error pages, such as:
- Using a JavaScript redirect to a page that does respond with a 404 status code.
- Adding a noindex tag to the page that’s failing along with some kind of error message like 404 Page Not Found. This will be treated as a soft 404 since the actual status code returned will be a 200 okay.
JavaScript redirects are OK, but not preferred
SEOs are used to 301/302 redirects, which are server-side. JavaScript is typically run client-side. Server-side redirects and even meta refresh redirects will be easier for Google to process than JavaScript redirects since it won’t have to render the page to see them.
JavaScript redirects will still be seen and processed during rendering and should be OK in most cases—they’re just not as ideal as other redirect types. They are treated as permanent redirects and still pass all signals like PageRank.
You can often find these redirects in the code by looking for “window.location.href”. The redirects could potentially be in the config file as well. In the Next.js config, there’s a redirect function you can use to set redirects. In other systems, you may find them in the router.
Internationalization issues
There are usually a few module options for different frameworks that support some features needed for internationalization like hreflang. They’ve commonly been ported to the different systems and include i18n, intl or, many times, the same modules used for header tags like Helmet can be used to add the needed tags.
We flag hreflang issues in the Localization report in Site Audit. We also ran a study and found that 67% of domains using hreflang have issues.
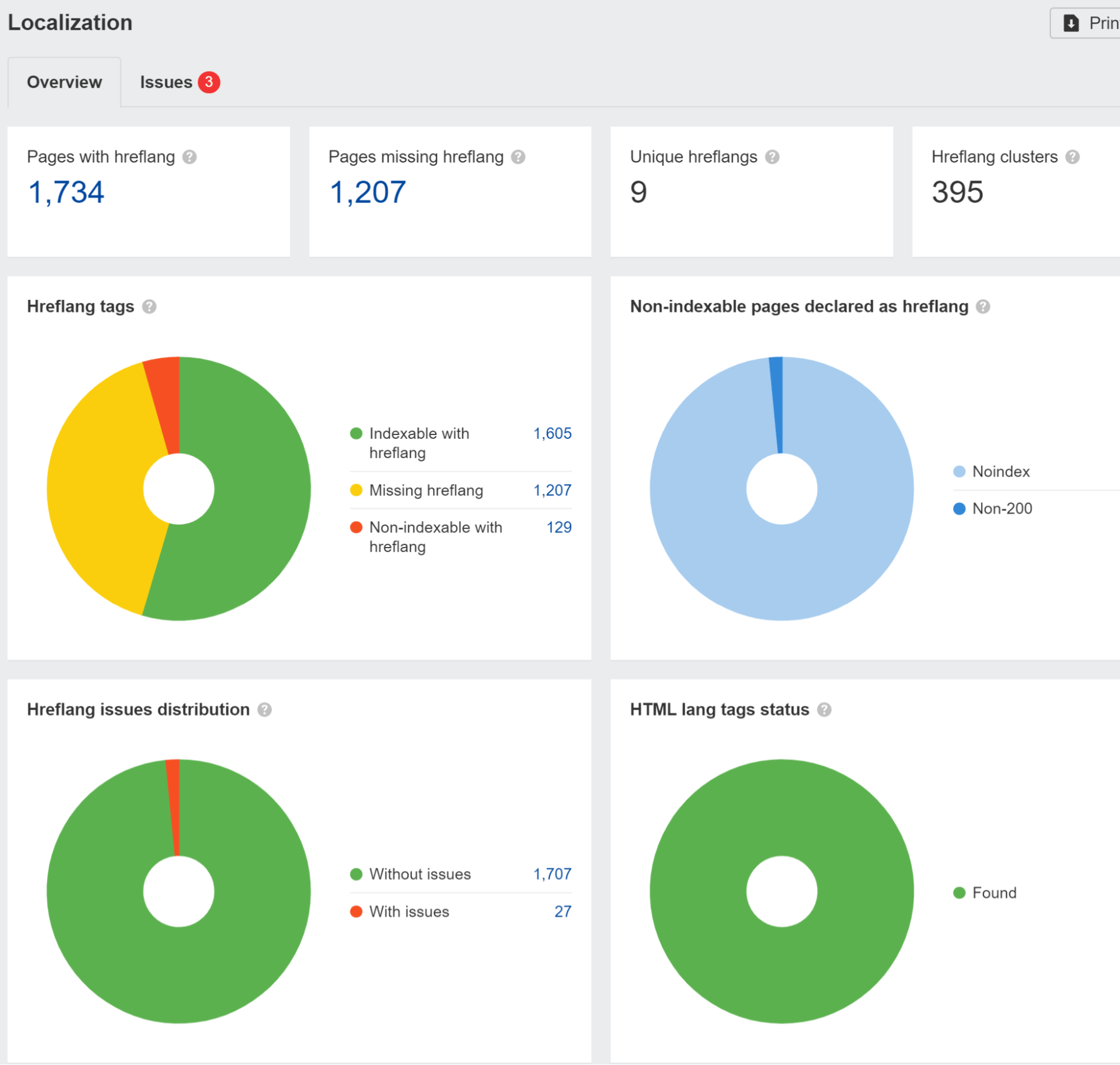
You also need to be wary if your site is blocking or treating visitors from a specific country or using a particular IP in different ways. This can cause your content not to be seen by Googlebot. If you have logic redirecting users, you may want to exclude bots from this logic.
We’ll let you know if this is happening when setting up a project in Site Audit.

Use structured data
JavaScript can be used to generate or to inject structured data on your pages. It’s pretty common to do this with JSON-LD and not likely to cause any issues, but run some tests to make sure everything comes out like you expect.
We’ll flag any structured data we see in the Issues report in Site Audit. Look for the “Structured data has schema.org validation” error. We’ll tell you exactly what is wrong for each page.
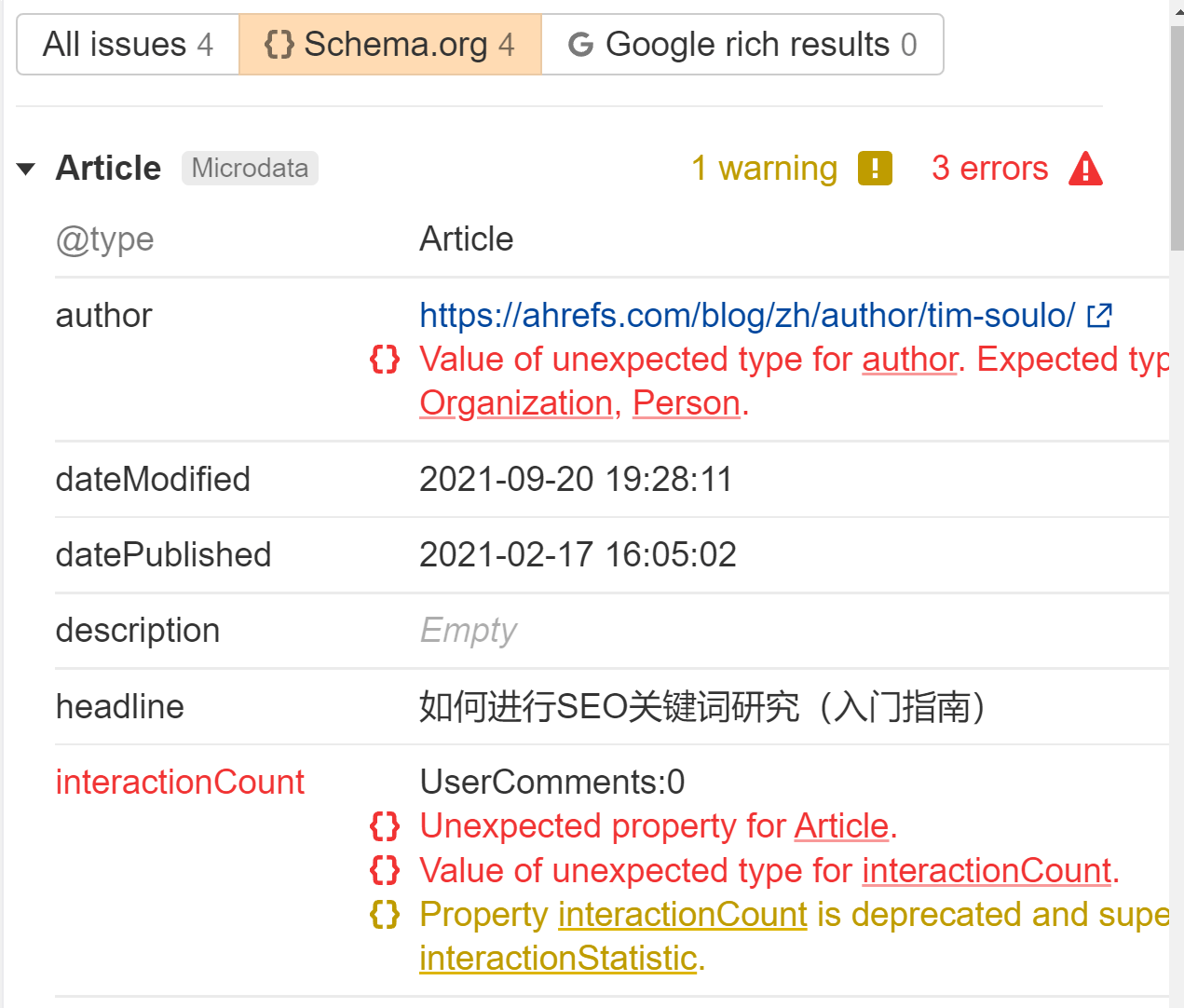
Use standard format links
Links to other pages should be in the web standard format. Internal and external links need to be an <a> tag with an href attribute. There are many ways you can make links work for users with JavaScript that are not search-friendly.
Good:
<a href=”/page”>simple is good</a>
<a href=”/page” onclick=”goTo(‘page’)”>still okay</a>
Bad:
<a onclick=”goTo(‘page’)”>nope, no href</a>
<a href=”javascript:goTo(‘page’)”>nope, missing link</a>
<a href=”javascript:void(0)”>nope, missing link</a>
<span onclick=”goTo(‘page’)”>not the right HTML element</span>
<option value="page">nope, wrong HTML element</option>
<a href=”#”>no link</a>
Button, ng-click, there are many more ways this can be done incorrectly.
In my experience, Google still processes many of the bad links and crawls them, but I’m not sure how it treats them as far passing signals like PageRank. The web is a messy place, and Google’s parsers are often fairly forgiving.
It’s also worth noting that internal links added with JavaScript will not get picked up until after rendering. That should be relatively quick and not a cause for concern in most cases.
Use file versioning to solve for impossible states being indexed
Google heavily caches all resources on its end. I’ll talk about this a bit more later, but you should know that its system can lead to some impossible states being indexed. This is a quirk of its systems. In these cases, previous file versions are used in the rendering process, and the indexed version of a page may contain parts of older files.
You can use file versioning or fingerprinting (file.12345.js) to generate new file names when significant changes are made so that Google has to download the updated version of the resource for rendering.
You may not see what is shown to Googlebot
You may need to change your user-agent to properly diagnose some issues. Content can be rendered differently for different user-agents or even IPs. You should check what Google actually sees with its testing tools, and I’ll cover those in a bit.
You can set a custom user-agent with Chrome DevTools to troubleshoot sites that prerender based on specific user-agents, or you can easily do this with our toolbar as well.
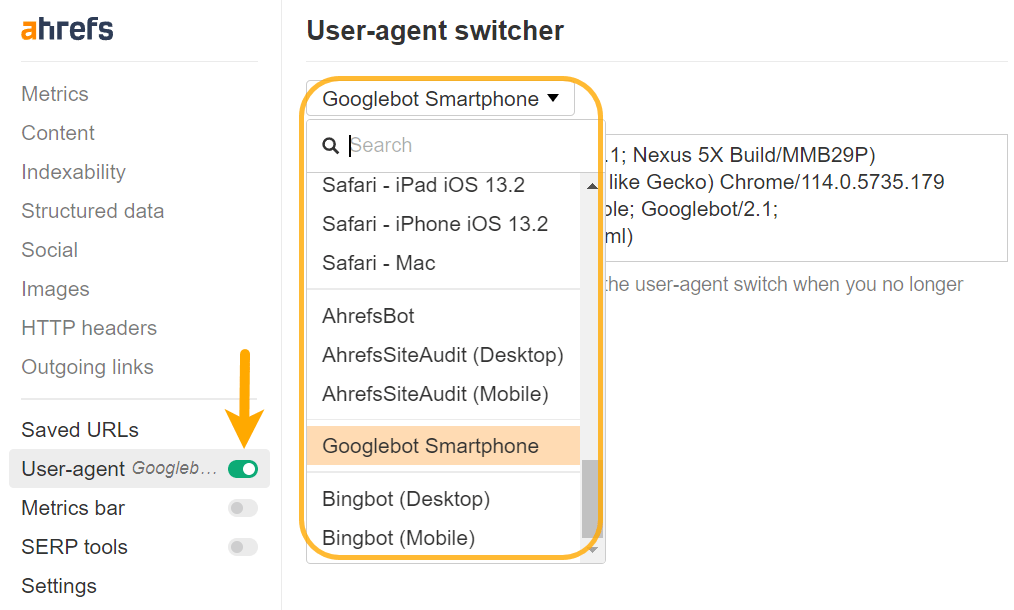
Use polyfills for unsupported features
There can be features used by developers that Googlebot doesn’t support. Your developers can use feature detection. And if there’s a missing feature, they can choose to either skip that functionality or use a fallback method with a polyfill to see if they can make it work.
This is mostly an FYI for SEOs. If you see something you think Google should be seeing and it’s not seeing it, it could be because of the implementation.
Use lazy loading
Since I originally wrote this, lazy loading has mostly moved from being JavaScript-driven to being handled by browsers.
You may still run into some JavaScript-driven lazy load setups. For the most part, they’re probably fine if the lazy loading is for images. The main thing I’d check is to see if content is being lazy loaded. Refer back to the “Check if Google sees your content” section above. These kinds of setups have caused problems with the content being picked up correctly.
Infinite scroll issues
If you have an infinite scroll setup, I still recommend a paginated page version so that Google can still crawl properly.
Another issue I’ve seen with this setup is, occasionally, two pages get indexed as one. I’ve seen this a few times when people said they couldn’t get their page indexed. But I’ve found their content indexed as part of another page that’s usually the previous post from them.
My theory is that when Google resized the viewport to be longer (more on this later), it triggered the infinite scroll and loaded another article in when it was rendering. In this case, what I recommend is to block the JavaScript file that handles the infinite scrolling so the functionality can’t trigger.
Performance issues
A lot of the JavaScript frameworks take care of a ton of modern performance optimization for you.
All of the traditional performance best practices still apply, but you get some fancy new options. Code splitting chunks the files into smaller files. Tree shaking breaks out needed parts, so you’re not loading everything for every page like you’d see in traditional monolithic setups.
JavaScript setups done well are a thing of beauty. JavaScript setups that aren’t done well can be bloated and cause long load times.
Check out our Core Web Vitals guide for more about website performance.
JavaScript sites use more crawl budget
JavaScript XHR requests eat crawl budget, and I mean they gobble it down. Unlike most other resources that are cached, these get fetched live during the rendering process.
Another interesting detail is that the rendering service tries not to fetch resources that don’t contribute to the content of the page. If it gets this wrong, you may be missing some content.
Workers aren’t supported, or are they?
While Google historically says that it rejects service workers and service workers can’t edit the DOM, Google’s own Martin Splitt indicated that you may get away with using web workers sometimes.
Use HTTP connections
Googlebot supports HTTP requests but doesn’t support other connection types like WebSockets or WebRTC. If you’re using those, provide a fallback that uses HTTP connections.
One “gotcha” with JavaScript sites is they can do partial updates of the DOM. Browsing to another page as a user may not update some aspects like title tags or canonical tags in the DOM, but this may not be an issue for search engines.
Google loads each page stateless like it’s a fresh load. It’s not saving previous information and not navigating between pages.
I’ve seen SEOs get tripped up thinking there is a problem because of what they see after navigating from one page to another, such as a canonical tag that doesn’t update. But Google may never see this state.
Devs can fix this by updating the state using what’s called the History API. But again, it may not be a problem. A lot of time, it’s just SEOs making trouble for the developers because it looks weird to them. Refresh the page and see what you see. Or better yet, run it through one of Google’s testing tools to see what it sees.
Speaking of its testing tools, let’s talk about those.
Google testing tools
Google has several testing tools that are useful for JavaScript.
URL Inspection tool in Google Search Console
This should be your source of truth. When you inspect a URL, you’ll get a lot of info about what Google saw and the actual rendered HTML from its system.
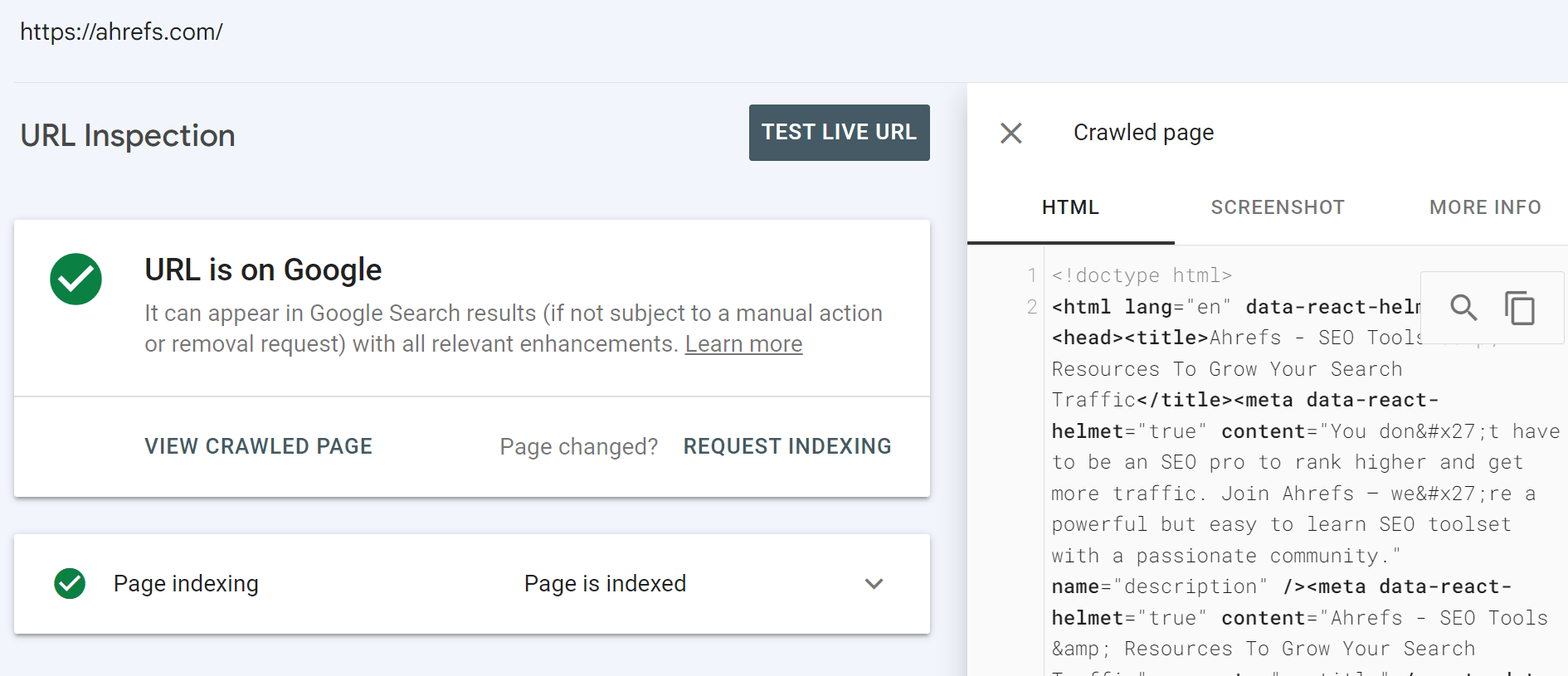
You have the option to run a live test as well.
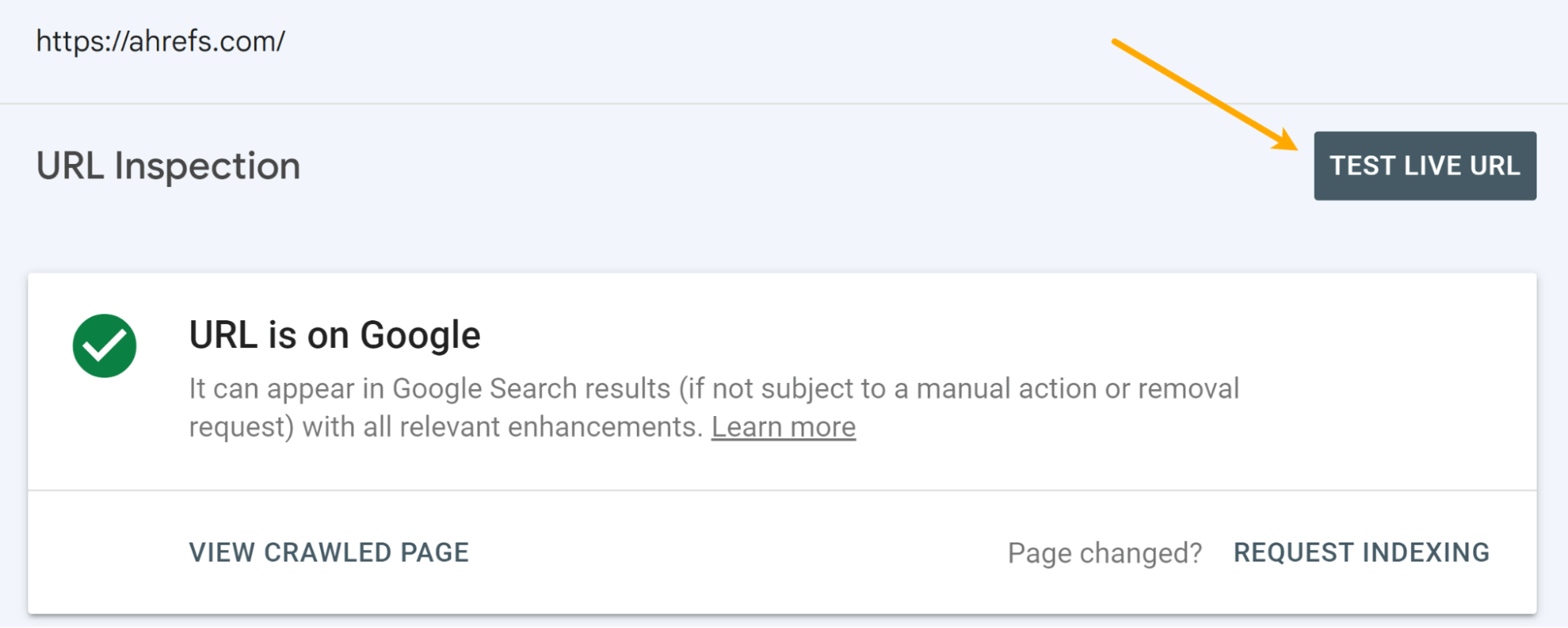
There are some differences between the main renderer and the live test. The renderer uses cached resources and is fairly patient. The live test and other testing tools use live resources, and they cut off rendering early because you’re waiting for a result. I’ll go into more detail about this in the rendering section later.
The screenshots in these tools also show pages with the pixels painted, which Google doesn’t actually do when rendering a page.
The tools are useful to see if content is DOM-loaded. The HTML shown in these tools is the rendered DOM. You can search for a snippet of text to see if it was loaded in by default.
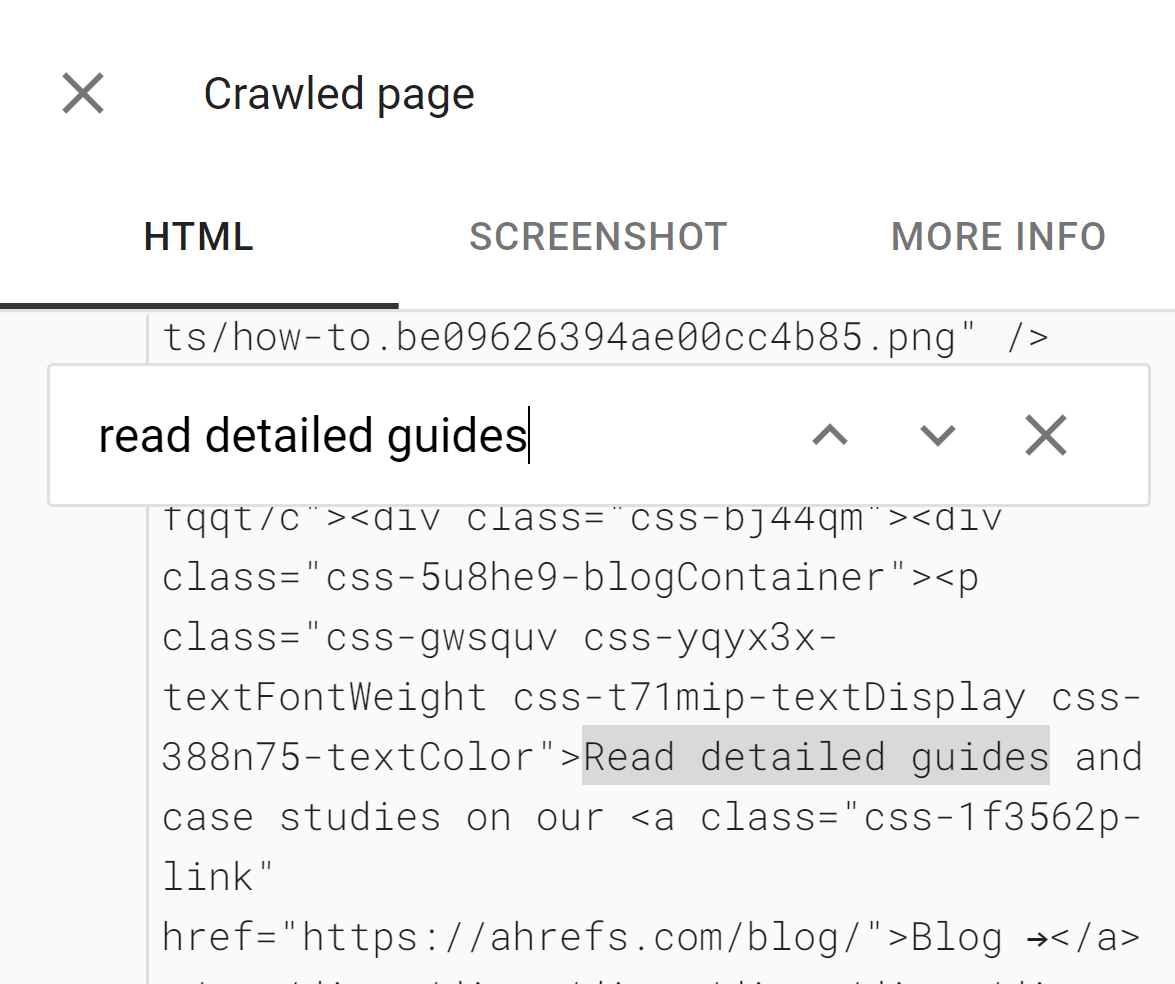
The tools will also show you resources that may be blocked and console error messages, which are useful for debugging.
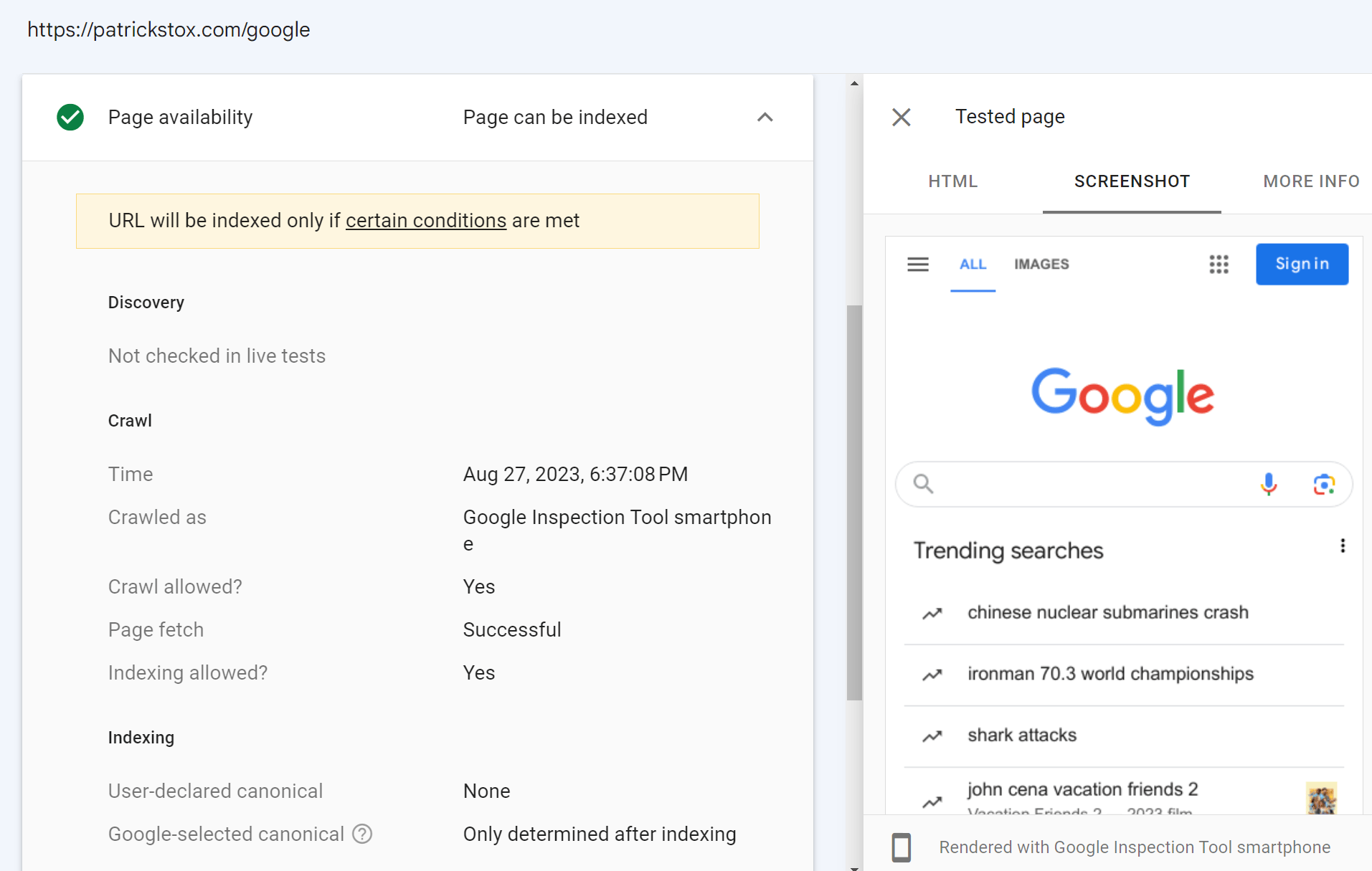
If you don’t have access to the Google Search Console property for a website, you can still run a live test on it. If you add a redirect on your own website on a property where you have Google Search Console access, then you can inspect that URL and the inspection tool will follow the redirect and show you the live test result for the page on the other domain.
In the screenshot below, I added a redirect from my site to Google’s homepage. The live test for this follows the redirect and shows me Google’s homepage. I do not actually have access to Google’s Google Search Console account, although I wish I did.
Rich Results Test tool
The Rich Results Test tool allows you to check your rendered page as Googlebot would see it for mobile or for desktop.
Mobile-Friendly Test tool
You can still use the Mobile-Friendly Test tool for now, but Google has announced it is shutting down in December 2023.
It has the same quirks as the other testing tools from Google.
Ahrefs
Ahrefs is the only major SEO tool that renders webpages when crawling the web, so we have data from JavaScript sites that no other tool does. We render ~200M pages a day, but that’s a fraction of what we crawl.
It allows us to check for JavaScript redirects. We can also show links we found inserted with JavaScript, which we show with a JS tag in the link reports:

In the drop-down menu for pages in Site Explorer, we also have an inspect option that lets you see the history of a page and compare it to other crawls. We have a JS marker there for pages that were rendered with JavaScript enabled.
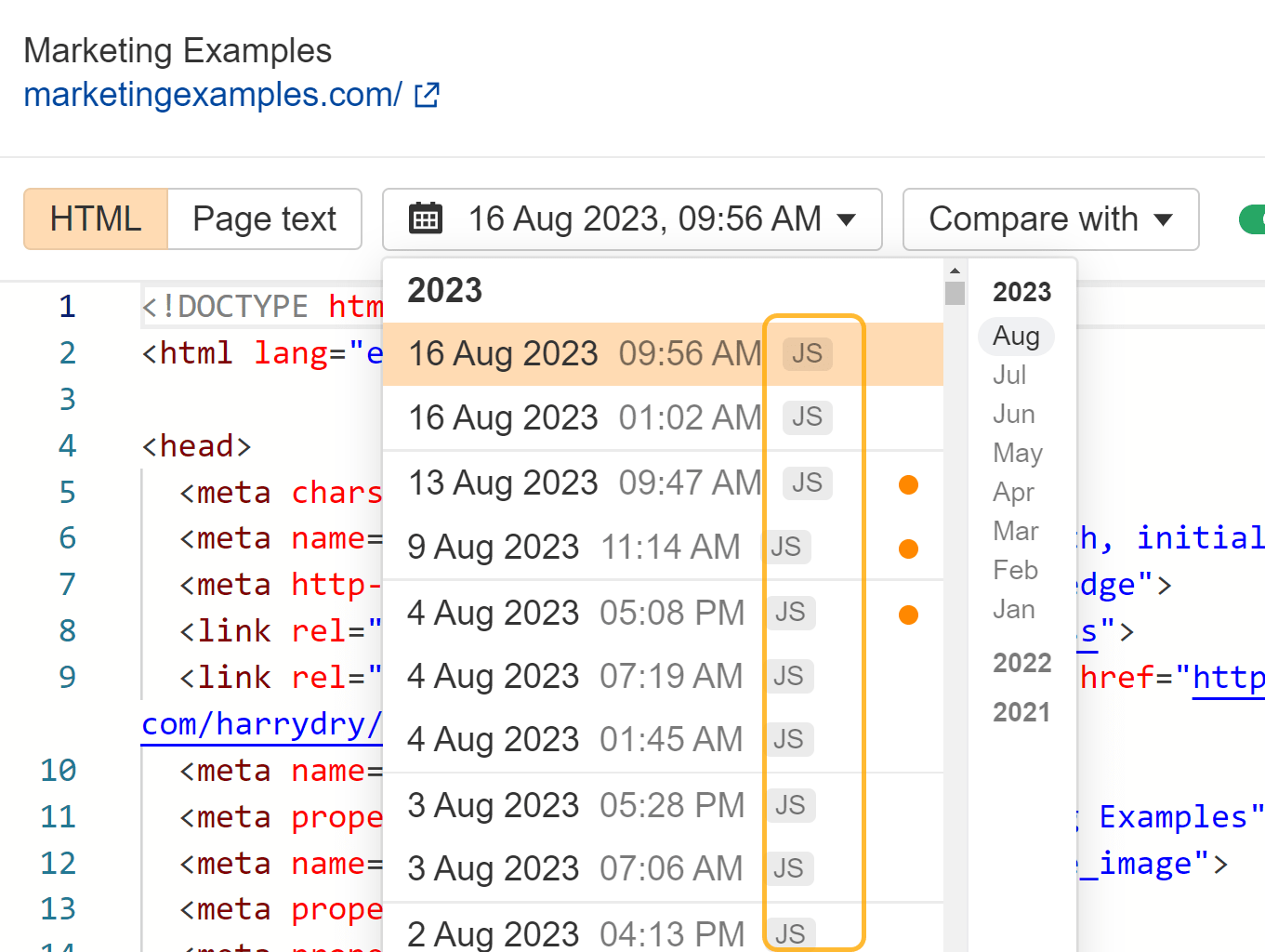
You can enable JavaScript in Site Audit crawls to unlock more data in your audits.
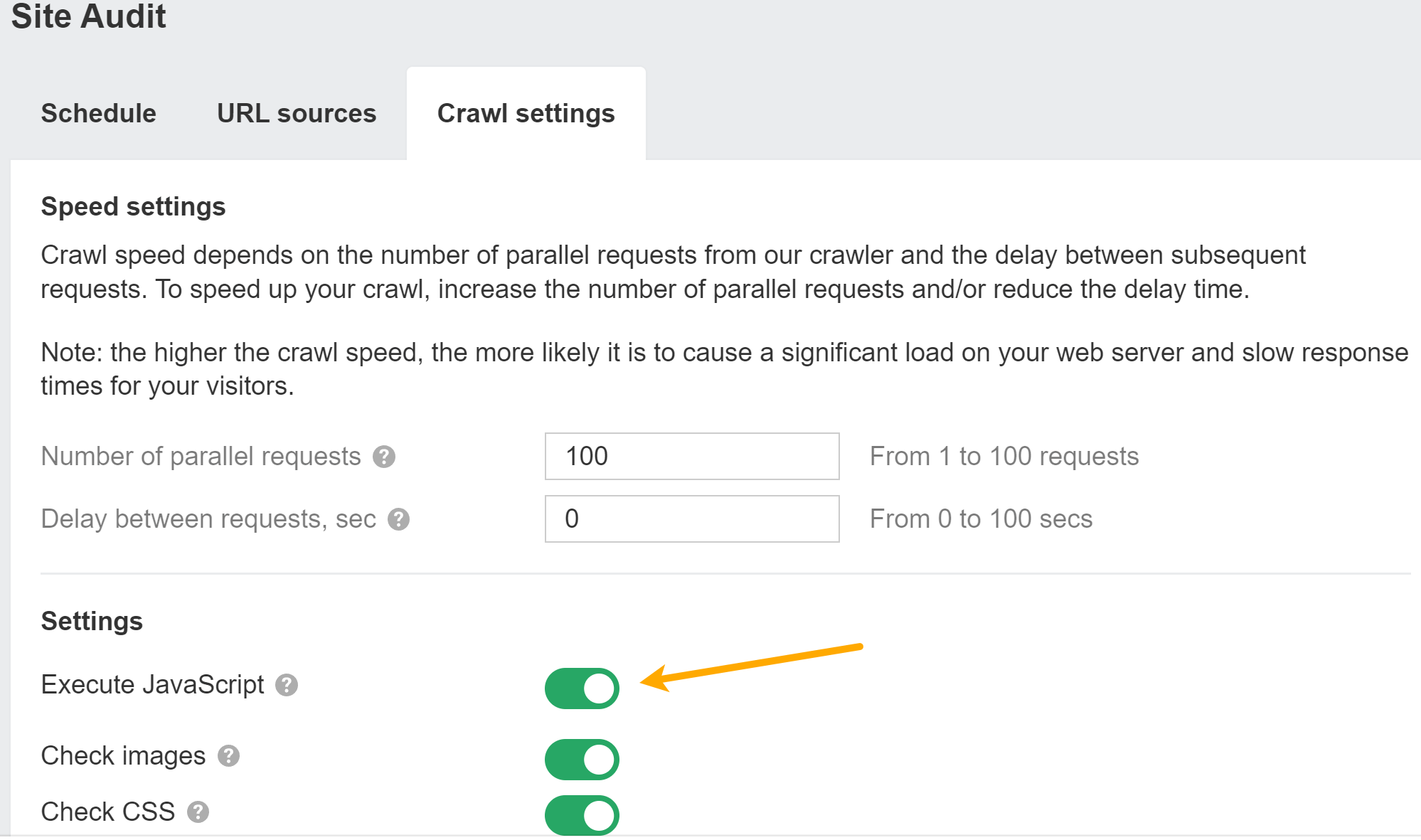
If you have JavaScript rendering enabled, we will provide the raw and rendered HTML for every page. Use the “magnifying glass” option next to a page in Page Explorer and go to “View source” in the menu. You can also compare against previous crawls and search within the raw or rendered HTML across all pages on the site.
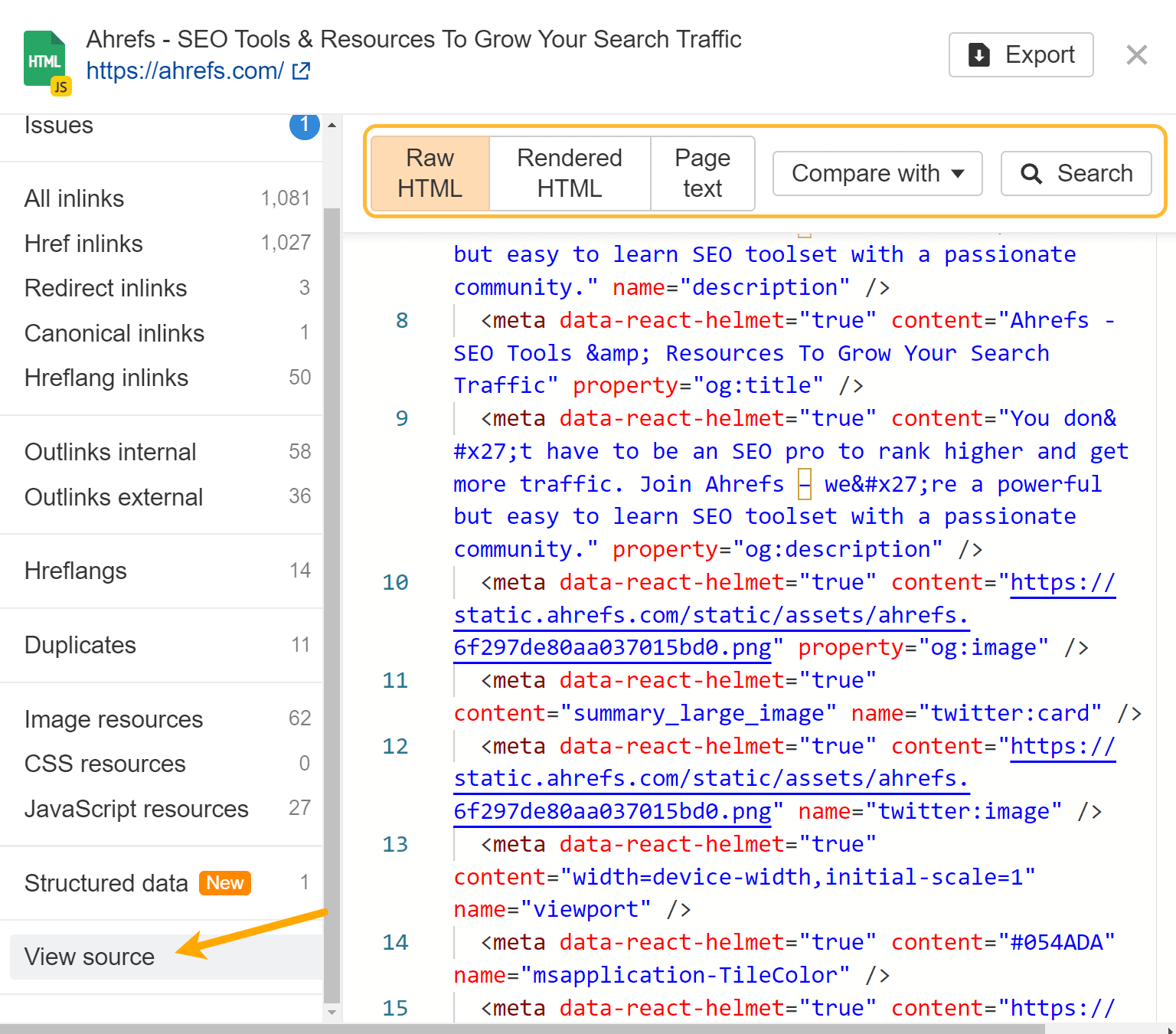
If you run a crawl without JavaScript and then another one with it, you can use our crawl comparison features to see differences between the versions.
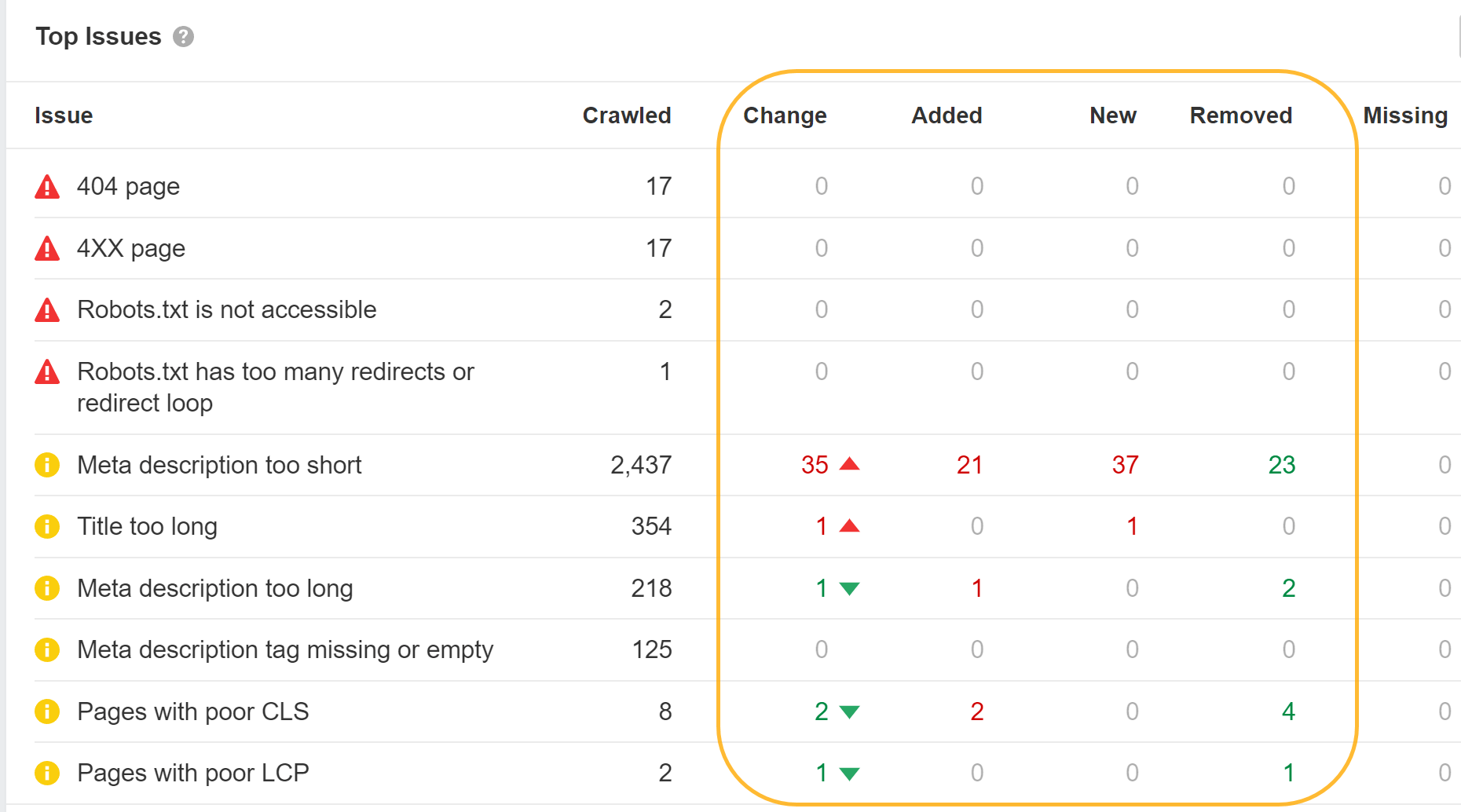
Ahrefs’ SEO Toolbar also supports JavaScript and allows you to compare HTML to rendered versions of tags.
View source vs. inspect
When you right-click in a browser window, you’ll see a couple of options for viewing the source code of the page and for inspecting the page. View source is going to show you the same as a GET request would. This is the raw HTML of the page.

Inspect shows you the processed DOM after changes have been made and is closer to the content that Googlebot sees. It’s the page after JavaScript has run and made changes to it.
You should mostly use inspect over view source when working with JavaScript.
Sometimes you need to check view source
Because Google looks at both raw and rendered HTML for some issues, you may still need to check view source at times. For instance, if Google’s tools are telling you the page is marked noindex, but you don’t see a noindex tag in the rendered HTML, it’s possible that it was there in the raw HTML and overwritten.
For things like noindex, nofollow, and canonical tags, you may need to check the raw HTML since issues can carry over. Remember that Google will take the most restrictive statements it saw for the meta robots tags, and it’ll ignore canonical tags when you show it multiple canonical tags.
Don’t browse with JavaScript turned off
I’ve seen this recommended way too many times. Google renders JavaScript, so what you see without JavaScript is not at all like what Google sees. This is just silly.
Don’t use Google Cache
Google’s cache is not a reliable way to check what Googlebot sees. What you typically see in the cache is the raw HTML snapshot. Your browser then fires the JavaScript that is referenced in the HTML. It’s not what Google saw when it rendered the page.
To complicate this further, websites may have their Cross-Origin Resource Sharing (CORS) policy set up in a way that the required resources can’t be loaded from a different domain.
The cache is hosted on webcache.googleusercontent.com. When that domain tries to request the resources from the actual domain, the CORS policy says, “Nope, you can’t access my files.” Then the files aren’t loaded, and the page looks broken in the cache.
The cache system was made to see the content when a website is down. It’s not particularly useful as a debug tool.
In the early days of search engines, a downloaded HTML response was enough to see the content of most pages. Thanks to the rise of JavaScript, search engines now need to render many pages as a browser would so they can see content as how a user sees it.
The system that handles the rendering process at Google is called the Web Rendering Service (WRS). Google has provided a simplistic diagram to cover how this process works.
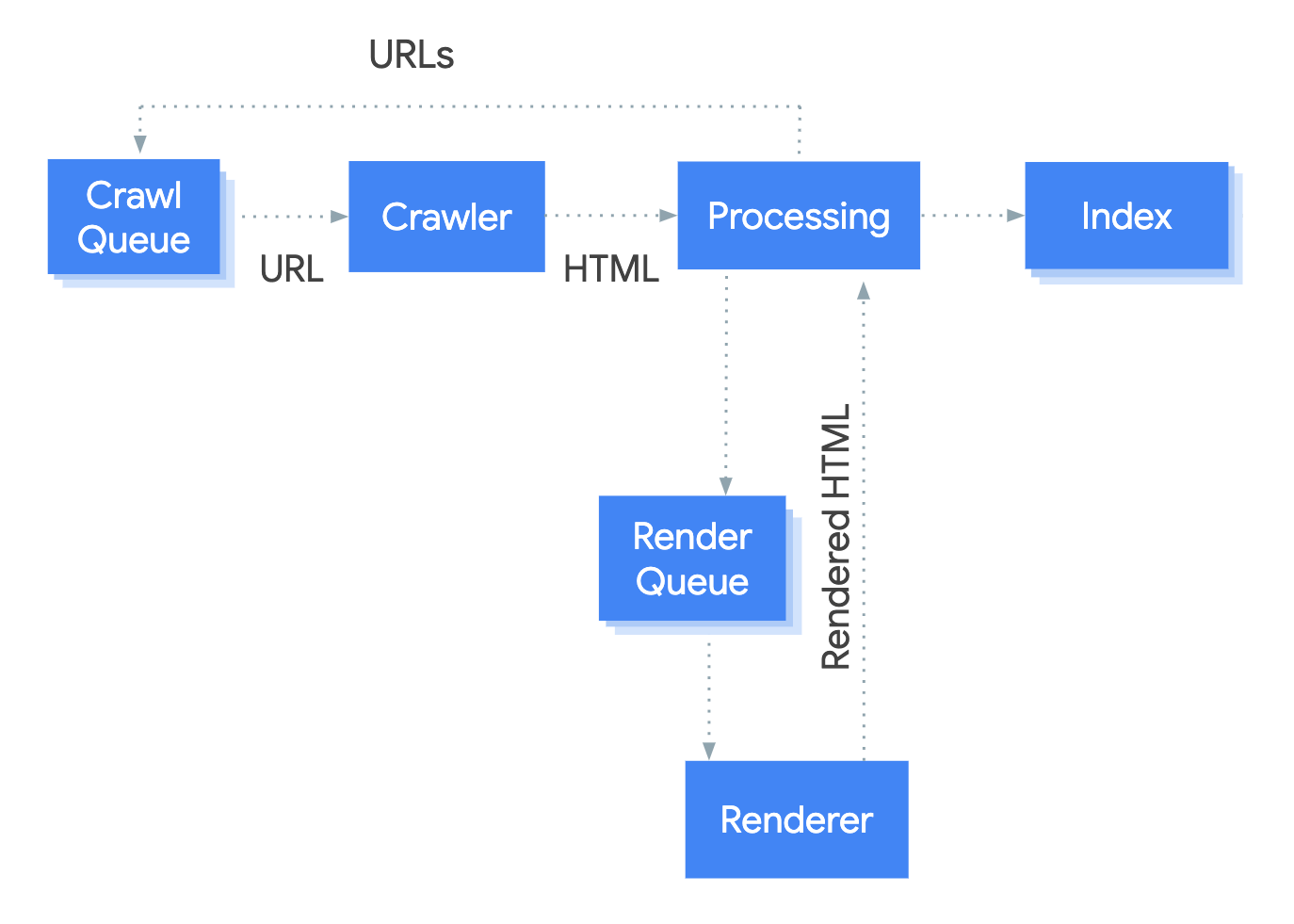
Let’s say we start the process at URL.
1. Crawler
The crawler sends GET requests to the server. The server responds with headers and the contents of the file, which then gets saved. The headers and the content typically come in the same request.
The request is likely to come from a mobile user-agent since Google is on mobile-first indexing now, but it also still crawls with the desktop user-agent.
The requests mostly come from Mountain View (CA, U.S.), but it also does some crawling for locale-adaptive pages outside of the U.S. As I mentioned earlier, this can cause issues if sites are blocking or treating visitors in a specific country in different ways.
It’s also important to note that while Google states the output of the crawling process as HTML on the image above, in reality, it’s crawling and storing the resources needed to build the page like the HTML, JavaScript files, and CSS files. There’s also a 15 MB max size limit for HTML files.
2. Processing
There are a lot of systems obfuscated by the term “Processing” in the image. I’m going to cover a few of these that are relevant to JavaScript.
Resources and links
Google does not navigate from page to page as a user would. Part of “Processing” is to check the page for links to other pages and files needed to build the page. These links are pulled out and added to the crawl queue, which is what Google is using to prioritize and schedule crawling.
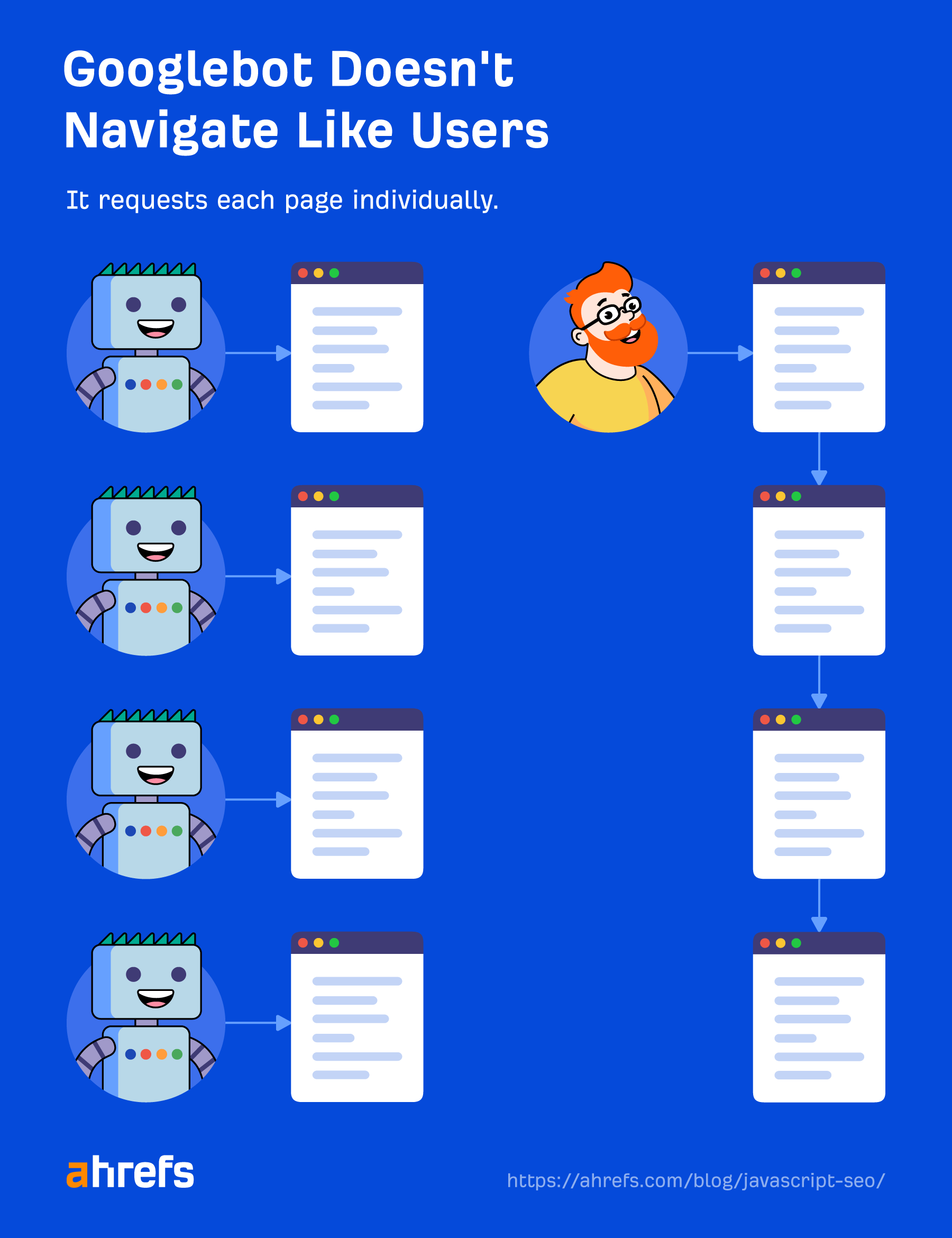
Google will pull resource links (CSS, JS, etc.) needed to build a page from things like <link> tags.
As I mentioned earlier, internal links added with JavaScript will not get picked up until after rendering. That should be relatively quick and not a cause for concern in most cases. Things like news sites may be the exception where every second counts.
Caching
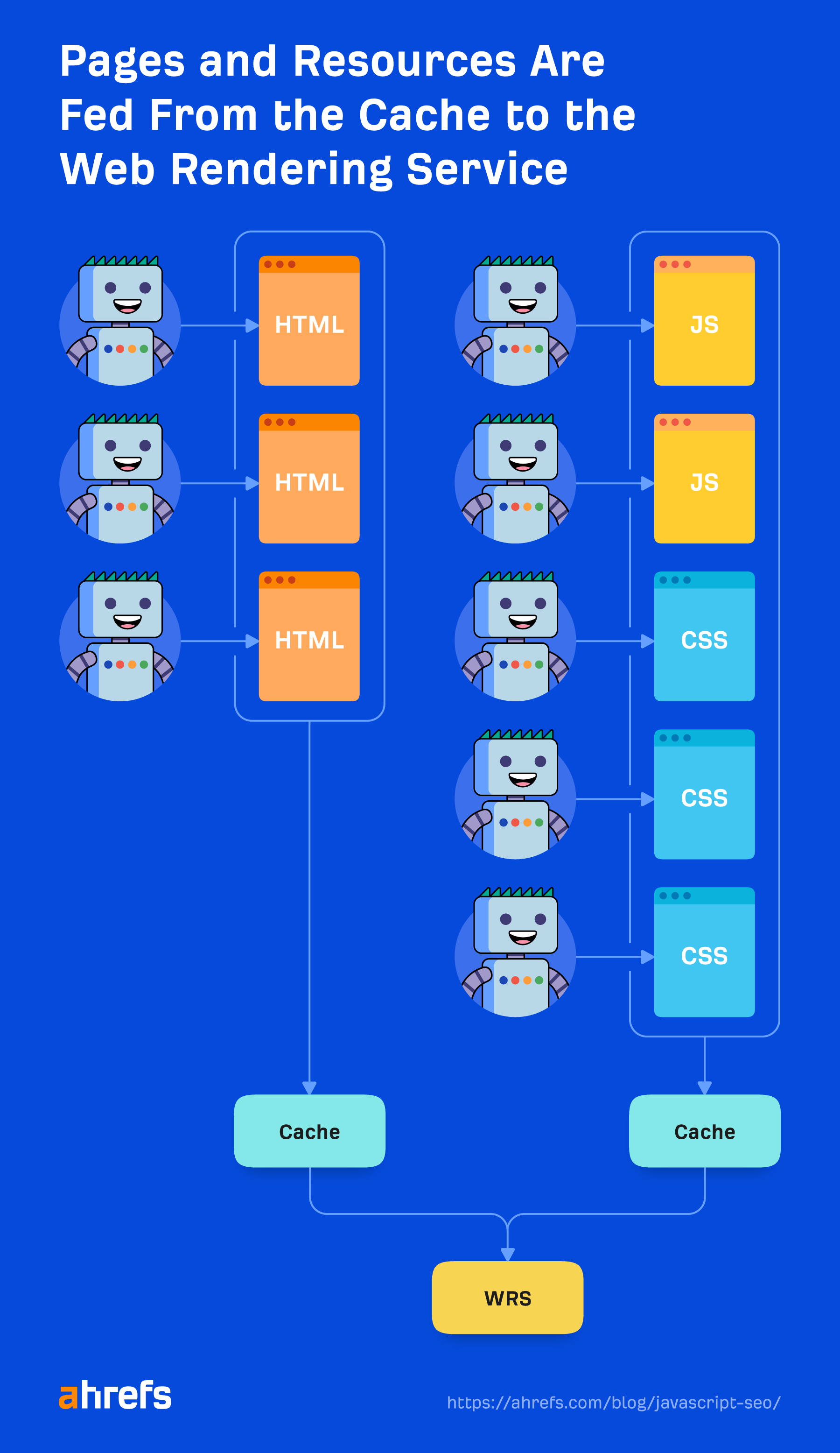
Every file that Google downloads, including HTML pages, JavaScript files, CSS files, etc., is going to be aggressively cached. Google will ignore your cache timings and fetch a new copy when it wants to. I’ll talk a bit more about this and why it’s important in the “Renderer” section.
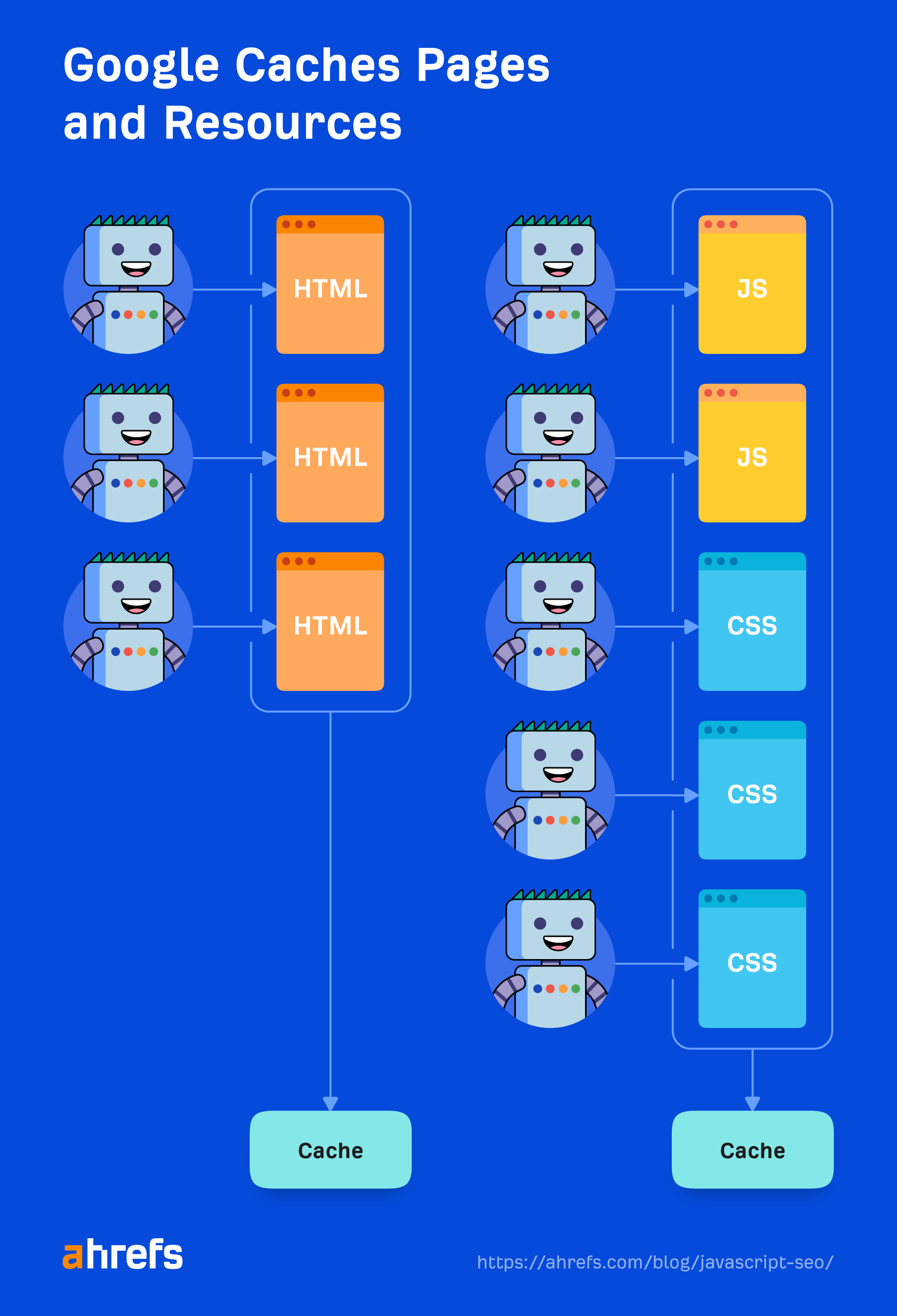
Duplicate elimination
Duplicate content may be eliminated or deprioritized from the downloaded HTML before it gets sent to rendering. I already talked about this in the “Duplicate content” section above.
Most restrictive directives
As I mentioned earlier, Google will choose the most restrictive statements between HTML and the rendered version of a page. If JavaScript changes a statement and that conflicts with the statement from HTML, Google will simply obey whichever is the most restrictive. Noindex will override index, and noindex in HTML will skip rendering altogether.
3. Render queue
One of the biggest concerns from many SEOs with JavaScript and two-stage indexing (HTML then rendered page) is that pages may not get rendered for days or even weeks. When Google looked into this, it found pages went to the renderer at a median time of five seconds, and the 90th percentile was minutes. So the amount of time between getting the HTML and rendering the pages should not be a concern in most cases.
However, Google doesn’t render all pages. Like I mentioned previously, a page with a robots meta tag or header containing a noindex tag will not be sent to the renderer. It won’t waste resources rendering a page it can’t index anyway.
It also has quality checks in this process. If it looks at the HTML or can reasonably determine from other signals or patterns that a page isn’t good enough quality to index, then it won’t bother sending that to the renderer.
There’s also a quirk with news sites. Google wants to index pages on news sites fast so it can index the pages based on the HTML content first—and come back later to render these pages.
4. Renderer
The renderer is where Google renders a page to see what a user sees. This is where it’s going to process the JavaScript and any changes made by JavaScript to the DOM.
For this, Google is using a headless Chrome browser that is now evergreen, which means it should use the latest Chrome version and support the latest features. Years ago, Google was rendering with Chrome 41, and many features were not supported at that time.
Google has more info on the WRS, which includes things like denying permissions, being stateless, flattening light DOM and shadow DOM, and more that is worth reading.
Rendering at web-scale may be the eighth wonder of the world. It’s a serious undertaking and takes a tremendous amount of resources. Because of the scale, Google is taking many shortcuts with the rendering process to speed things up.
Cached resources
Google is relying heavily on caching resources. Pages are cached. Files are cached. Nearly everything is cached before being sent to the renderer. It’s not going out and downloading each resource for every page load, because that would be expensive for it and website owners. Instead, it uses these cached resources to be more efficient.
The exception to that is XHR requests, which the renderer will do in real time.
There’s no five-second timeout
A common SEO myth is that Google only waits five seconds to load your page. While it’s always a good idea to make your site faster, this myth doesn’t really make sense with the way Google caches files mentioned above. It’s already loading a page with everything cached in its systems, not making requests for fresh resources.
If it only waited five seconds, it would miss a lot of content.
The myth likely comes from the testing tools like the URL Inspection tool where resources are fetched live instead of cached, and they need to return a result to users within a reasonable amount of time. It could also come from pages not being prioritized for crawling, which makes people think they’re waiting a long time to render and index them.
There is no fixed timeout for the renderer. It runs with a sped-up timer to see if anything is added at a later time. It also looks at the event loop in the browser to see when all of the actions have been taken. It’s really patient, and you should not be concerned about any specific time limit.
It is patient, but it also has safeguards in place in case something gets stuck or someone is trying to mine Bitcoin on its pages. Yes, it’s a thing. We had to add safeguards for Bitcoin mining as well and even published a study about it.
What Googlebot sees
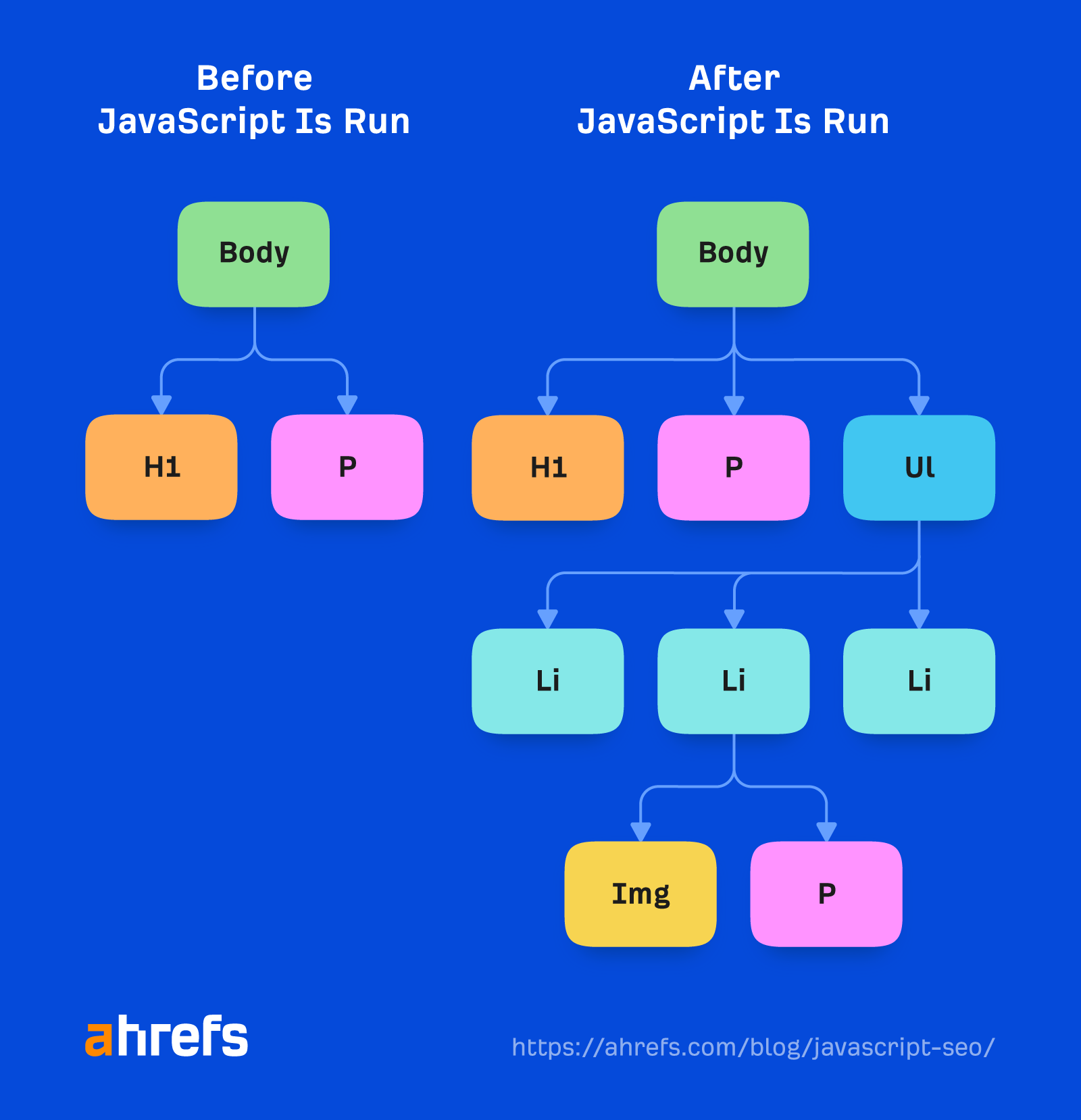
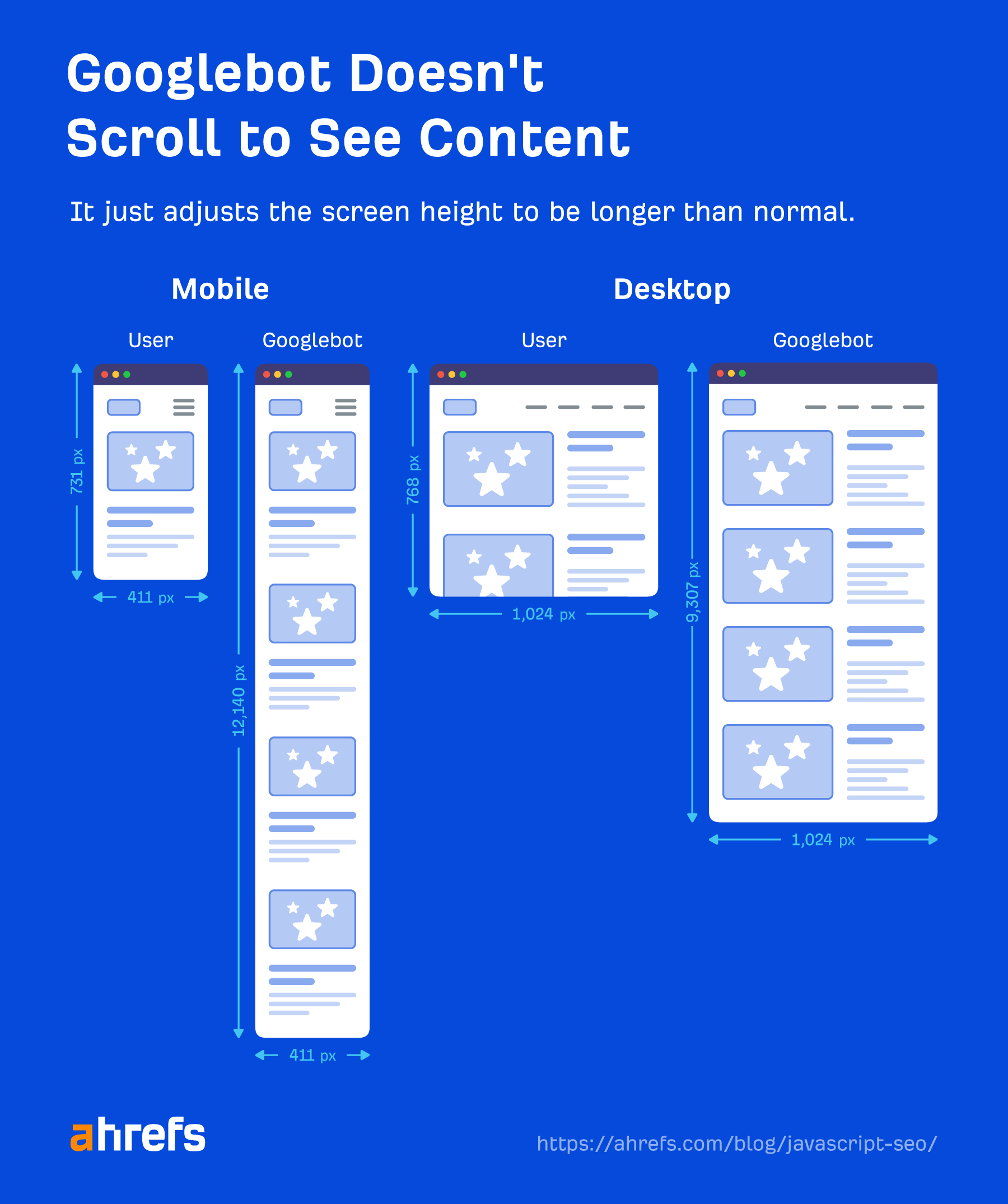
Googlebot doesn’t take action on webpages. It’s not going to click things or scroll, but that doesn’t mean it doesn’t have workarounds. As long as content is loaded in the DOM without a needed action, Google will see it. If it’s not loaded into the DOM until after a click, then the content won’t be found.
Google doesn’t need to scroll to see your content either because it has a clever workaround to see the content. For mobile, it loads the page with a screen size of 411×731 pixels and resizes the length to 12,140 pixels.
Essentially, it becomes a really long phone with a screen size of 411×12140 pixels. For desktop, it does the same and goes from 1024×768 pixels to 1024×9307 pixels. I haven’t seen any recent tests for these numbers, and it may change depending on how long the pages are.
Another interesting shortcut is that Google doesn’t paint the pixels during the rendering process. It takes time and additional resources to finish a page load, and it doesn’t really need to see the final state with the pixels painted. Besides, graphics cards are expensive between gaming, crypto mining, and AI.
Google just needs to know the structure and the layout, and it gets that without having to actually paint the pixels. As Martin puts it:
In Google search we don’t really care about the pixels because we don’t really want to show it to someone. We want to process the information and the semantic information so we need something in the intermediate state. We don’t have to actually paint the pixels.
A visual may help explain what is cut out a bit better. In Chrome Dev Tools, if you run a test on the “Performance” tab, you get a loading chart. The solid green part here represents the painting stage. For Googlebot, that never happens, so it saves resources.

Gray = Downloads
Blue = HTML
Yellow = JavaScript
Purple = Layout
Green = Painting
5. Crawl queue
Google has a resource that talks a bit about crawl budget. But you should know that each site has its own crawl budget, and each request has to be prioritized. Google also has to balance crawling your pages vs. every other page on the internet.
Newer sites in general or sites with a lot of dynamic pages will likely be crawled slower. Some pages will be updated less often than others, and some resources may also be requested less frequently.
There are lots of options when it comes to rendering JavaScript. Google has a solid chart that I’m just going to show. Any kind of SSR, static rendering, and prerendering setup is going to be fine for search engines. Gatsby, Next, Nuxt, etc., are all great.

The most problematic one is going to be full client-side rendering where all of the rendering happens in the browser. While Google will probably be OK client-side rendering, it’s best to choose a different rendering option to support other search engines.
Bing also has support for JavaScript rendering, but the scale is unknown. Yandex and Baidu have limited support from what I’ve seen, and many other search engines have little to no support for JavaScript. Our own search engine, Yep, has support, and we render ~200M pages per day. But we don’t render every page we crawl.
There’s also the option of dynamic rendering, which is rendering for certain user-agents. This is a workaround and, to be honest, I never recommended it and am glad Google is recommending against it now as well.
Situationally, you may want to use it to render for certain bots like search engines or even social media bots. Social media bots don’t run JavaScript, so things like OG tags won’t be seen unless you render the content before serving it to them.
Practically, it makes setups more complex and harder for SEOs to troubleshoot. It’s definitely cloaking, even though Google says it’s not and that it’s OK with it.
Note
If you were using the old AJAX crawling scheme with hashbangs (#!), do know this has been deprecated and is no longer supported.
Final thoughts
JavaScript is not something for SEOs to fear. Hopefully, this article has helped you understand how to work with it better.
Don’t be afraid to reach out to your developers and work with them and ask them questions. They are going to be your greatest allies in helping to improve your JavaScript site for search engines.
Have questions? Let me know on Twitter.
منبع: https://ahrefs.com/blog/javascript-seo/