
- Détection de contenu IA
- Méthodologie
- Résultats : auto-détection
- Résultats de l’auto-détection par l’IA de son propre contenu textuel
- Résultats : contenu paraphrasé à détection automatique
- Capture d’écran de l’auto-détection du contenu paraphrasé de l’IA
- Résultats : modèles d’IA détectant le contenu de chacun
- Conclusions et points à retenir
Les chercheurs ont testé l’idée selon laquelle un modèle d’IA pourrait avoir l’avantage de détecter automatiquement son propre contenu, car la détection exploitait la même formation et les mêmes ensembles de données. Ce qu’ils ne s’attendaient pas à découvrir, c’est que sur les trois modèles d’IA qu’ils ont testés, le contenu généré par l’un d’entre eux était si indétectable que même l’IA qui l’avait généré ne pouvait pas le détecter.
L’étude a été menée par des chercheurs du Département d’informatique de la Lyle School of Engineering de la Southern Methodist University.
Détection de contenu IA
De nombreux détecteurs d’IA sont formés pour rechercher les signaux révélateurs du contenu généré par l’IA. Ces signaux sont appelés « artefacts » et sont générés en raison de la technologie du transformateur sous-jacent. Mais d’autres artefacts sont propres à chaque modèle de base (le grand modèle linguistique sur lequel l’IA est basée).
Ces artefacts sont uniques à chaque IA et résultent de données d’entraînement distinctes et de réglages précis qui sont toujours différents d’un modèle d’IA à l’autre.
Les chercheurs ont découvert que c’est ce caractère unique qui permet à une IA de mieux réussir à identifier elle-même son propre contenu, bien mieux que d’essayer d’identifier le contenu généré par une autre IA.
Bard a de meilleures chances d’identifier le contenu généré par Bard et ChatGPT a un taux de réussite plus élevé pour identifier le contenu généré par ChatGPT, mais…
Les chercheurs ont découvert que cela n’était pas vrai pour le contenu généré par Claude. Claude avait du mal à détecter le contenu qu’il générait. Les chercheurs ont partagé une idée de la raison pour laquelle Claude n’a pas pu détecter son propre contenu et cet article en discute plus ،.
C’est l’idée derrière les tests de recherche :
« Étant donné que chaque modèle peut être entraîné différemment, il est difficile de créer un outil de détection unique pour détecter les artefacts créés par tous les outils d’IA générative possibles.
Ici, nous développons une approche différente appelée auto-détection, dans laquelle nous utilisons le modèle génératif lui-même pour détecter ses propres artefacts afin de distinguer son propre texte généré du texte écrit par l’homme.
Cela présenterait l’avantage que nous n’avons pas besoin d’apprendre à détecter tous les modèles d’IA génératifs, mais que nous avons uniquement besoin d’accéder à un modèle d’IA génératif pour la détection.
C’est un gros avantage dans un monde où de nouveaux modèles sont continuellement développés et formés.
Méthodologie
Les chercheurs ont testé trois modèles d’IA :
- ChatGPT-3.5 par OpenAI
- Barde par Google
- Claude par Anthropic
Tous les modèles utilisés étaient les versions de septembre 2023.
Un ensemble de données de cinquante sujets différents a été créé. Chaque modèle d’IA a reçu exactement les mêmes invites pour créer des essais d’environ 250 mots pour chacun des cinquante sujets qui ont généré cinquante essais pour chacun des trois modèles d’IA.
Chaque modèle d’IA a ensuite été invité de manière identique à paraphraser son propre contenu et à générer un essai supplémentaire qui était une réécriture de chaque essai original.
Ils ont également rassemblé cinquante essais générés par l’homme sur chacun des cinquante sujets. Tous les essais générés par l’homme ont été sélectionnés par la BBC.
Les chercheurs ont ensuite utilisé l’invite Zero Shot pour auto-détecter le contenu généré par l’IA.
L’invite Zero-shot est un type d’invite qui repose sur la capacité des modèles d’IA à effectuer des tâches pour lesquelles ils n’ont pas été spécifiquement formés.
Les chercheurs ont expliqué en outre leur méthodologie :
« Nous avons créé une nouvelle instance de chaque système d’IA lancé et posé avec une requête spécifique : « Si le texte suivant correspond à son modèle d’écriture et à son choix de mots. » La procédure est
répété pour les essais originaux, paraphrasés et humains, et les résultats sont enregistrés.Nous avons également ajouté le résultat de l’outil de détection d’IA ZeroGPT. Nous n’utilisons pas ce résultat pour comparer les performances mais comme référence pour montrer à quel point la tâche de détection est difficile.
Ils ont également noté qu’un taux d’exactitude de 50 % équivaut à une estimation, ce qui peut être considéré comme un niveau d’exactitude qui constitue un échec.
Résultats : auto-détection
Il convient de noter que les chercheurs ont reconnu que leur taux d’échantillonnage était faible et ont déclaré qu’ils ne prétendaient pas que les résultats étaient définitifs.
Vous trouverez ci-dessous un graphique montrant les taux de réussite de l’auto-détection par l’IA du premier lot d’essais. Les valeurs rouges représentent l’auto-détection de l’IA et le bleu représente les performances de l’outil de détection de l’IA ZeroGPT.
Résultats de l’auto-détection par l’IA de son propre contenu textuel
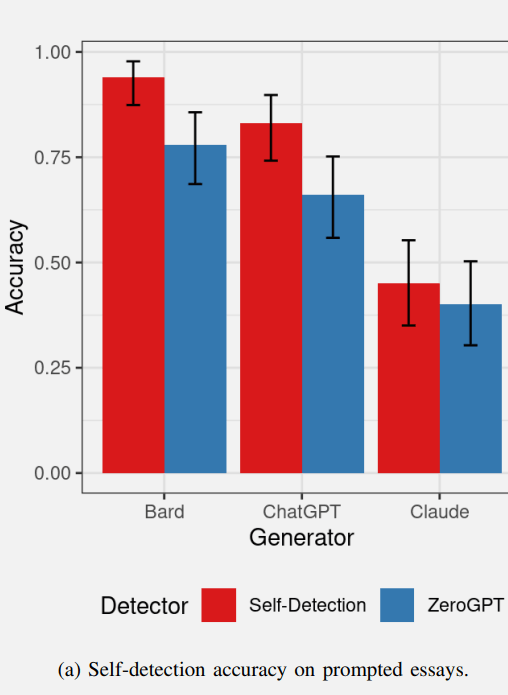
Bard a assez bien réussi à détecter son propre contenu et ChatGPT a également réussi à détecter son propre contenu.
ZeroGPT, l’outil de détection d’IA a très bien détecté le contenu Bard et a été légèrement moins performant dans la détection du contenu ChatGPT.
ZeroGPT n’a essentiellement pas réussi à détecter le contenu généré par Claude, avec des performances inférieures au seuil de 50 %.
Claude était la valeur aberrante du groupe car il était incapable de détecter lui-même son propre contenu, avec des performances bien inférieures à celles de Bard et ChatGPT.
Les chercheurs ont émis l’hypothèse qu’il se pourrait que les résultats de Claude contiennent moins d’artefacts détectables, expliquant pourquoi Claude et ZeroGPT n’ont pas pu détecter les essais de Claude comme étant générés par l’IA.
Ainsi, même si Claude n’a pas pu auto-détecter de manière fiable son propre contenu, cela s’est avéré être un signe que la sortie de Claude était de meilleure qualité en termes de production de moins d’artefacts d’IA.
ZeroGPT a mieux réussi à détecter le contenu généré par Bard qu’à détecter le contenu ChatGPT et Claude. Les chercheurs ont émis l’hypothèse qu’il se pourrait que Bard génère davantage d’artefacts détectables, ce qui rendrait Bard plus facile à détecter.
Ainsi, en termes de contenu d’auto-détection, Bard génère peut-être plus d’artefacts détectables et Claude génère moins d’artefacts.
Résultats : contenu paraphrasé à détection automatique
Les chercheurs ont émis l’hypothèse que les modèles d’IA seraient capables de détecter eux-mêmes leur propre texte paraphrasé, car les artefacts créés par le modèle (tels que détectés dans les essais originaux) devraient également être présents dans le texte réécrit.
Cependant, les chercheurs ont reconnu que les invites à écrire le texte et à paraphraser sont différentes car chaque réécriture est différente du texte original, ce qui pourrait par conséquent conduire à des résultats d’auto-détection différents pour l’auto-détection du texte paraphrasé.
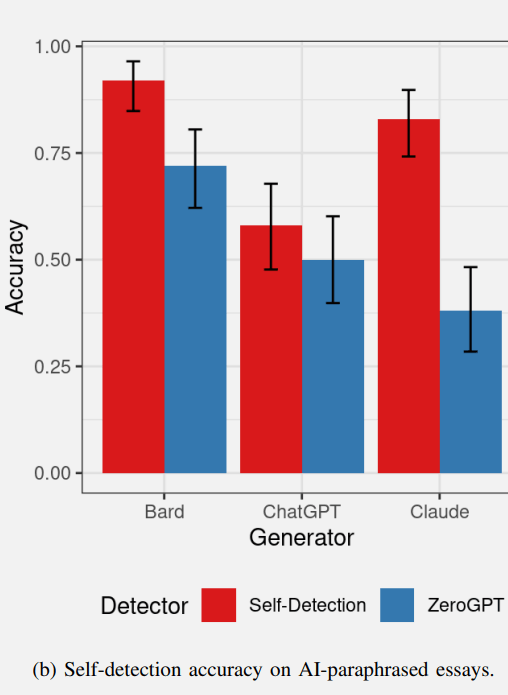
Les résultats de l’auto-détection du texte paraphrasé étaient en effet différents de l’auto-détection du test de rédaction original.
- Bard a pu auto-détecter le contenu paraphrasé à un rythme similaire.
- ChatGPT n’a pas été en mesure d’auto-détecter le contenu paraphrasé à un taux bien supérieur au taux de 50 % (ce qui équivaut à deviner).
- Les performances de ZeroGPT étaient similaires aux résultats du test précédent, avec des performances légèrement inférieures.
Le résultat le plus intéressant a peut-être été celui de Claude d’Anthropic.
Claude a pu détecter lui-même le contenu paraphrasé (mais il n’a pas pu détecter l’essai original lors du test précédent).
Il est intéressant de noter que les essais originaux de Claude contenaient apparemment si peu d’artefacts indiquant qu’ils étaient générés par l’IA que même Claude était incapable de le détecter.
Pourtant, il était capable d’auto-détecter la paraphrase, alors que ZeroGPT ne le pouvait pas.
Les chercheurs ont remarqué sur ce test :
“La découverte selon laquelle la paraphrase empêche ChatGPT de s’auto-détecter tout en augmentant la capacité de Claude à s’auto-détecter est très intéressante et peut être le résultat du fonctionnement interne de ces deux modèles de transformateurs.”
Capture d’écran de l’auto-détection du contenu paraphrasé de l’IA
Ces tests ont donné des résultats presque imprévisibles, notamment en ce qui concerne Claude d’Anthropic et cette tendance s’est poursuivie avec le test de la capacité des modèles d’IA à détecter le contenu de chacun, ce qui présentait un aspect intéressant.
Résultats : modèles d’IA détectant le contenu de chacun
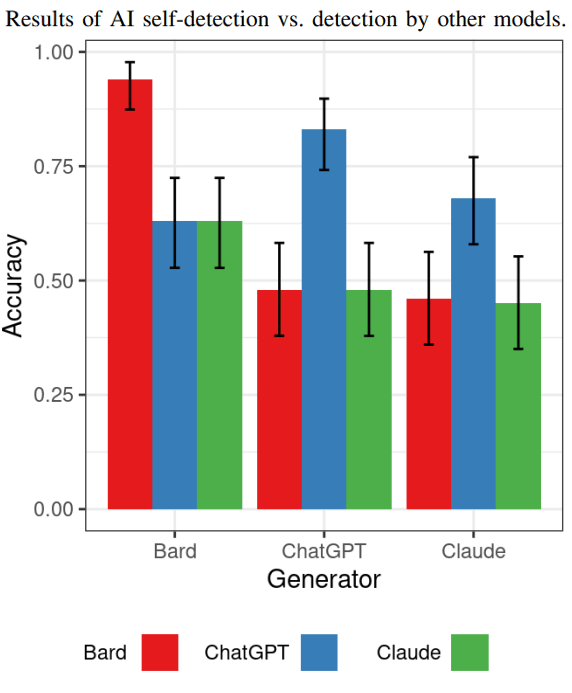
Le test suivant a montré dans quelle mesure chaque modèle d’IA était capable de détecter le contenu généré par les autres modèles d’IA.
S’il est vrai que Bard génère plus d’artefacts que les autres modèles, les autres modèles seront-ils capables de détecter facilement le contenu généré par Bard ?
Les résultats montrent que oui, le contenu généré par Bard est le plus facile à détecter par les autres modèles d’IA.
Concernant la détection du contenu généré par ChatGPT, Claude et Bard n’ont pas pu le détecter comme étant généré par l’IA (tout comme Claude n’a pas pu le détecter).
ChatGPT a été capable de détecter le contenu généré par Claude à un taux plus élevé que Bard et Claude, mais ce taux plus élevé n’était guère mieux que de deviner.
La découverte ici est que tous n’étaient pas très doués pour détecter le contenu des uns et des autres, ce qui, selon les chercheurs, pourrait montrer que l’auto-détection était un domaine d’étude prometteur.
Voici le graphique qui montre les résultats de ce test spécifique :
À ce stade, il convient de noter que les chercheurs ne prétendent pas que ces résultats sont concluants sur la détection de l’IA en général. L’objectif de la recherche était de tester si les modèles d’IA pouvaient réussir à détecter eux-mêmes leur propre contenu généré. La réponse est généralement oui, ils font un meilleur travail d’auto-détection, mais les résultats sont similaires à ceux trouvés avec ZEROGpt.
Les chercheurs ont commenté :
« L’auto-détection montre une puissance de détection similaire à celle de ZeroGPT, mais notez que le but de cette étude n’est pas de prétendre que l’auto-détection est supérieure aux autres méthodes, ce qui nécessiterait une vaste étude pour la comparer à de nombreuses méthodes de pointe. outils de détection de contenu art AI. Ici, nous étudions uniquement la capacité de base d’auto-détection des modèles.
Conclusions et points à retenir
Les résultats du test confirment que la détection du contenu généré par l’IA n’est pas une tâche facile. Bard est capable de détecter son propre contenu et le contenu paraphrasé.
ChatGPT peut détecter son propre contenu mais fonctionne moins bien sur son contenu paraphrasé.
Claude se démarque car il n’est pas capable d’auto-détecter de manière fiable son propre contenu, mais il a pu détecter le contenu paraphrasé, ce qui était plutôt étrange et inattendu.
Détecter les essais originaux de Claude et les essais paraphrasés était un défi pour ZeroGPT et pour les autres modèles d’IA.
Les chercheurs ont noté à propos des résultats de Claude :
« Ce résultat apparemment peu concluant mérite plus d’attention car il est motivé par deux causes confondues.
1) La capacité du modèle à créer du texte avec très peu d’artefacts détectables. Étant donné que l’objectif de ces systèmes est de générer un texte de type humain, moins d’artefacts difficiles à détecter signifient que le modèle se rapproche de cet objectif.
2) La capacité inhérente du modèle à s’auto-détecter peut être affectée par l’architecture utilisée, l’invite et les réglages fins appliqués.
Les chercheurs ont fait cette autre observation à propos de Claude :
« Seul Claude est indétectable. Cela indique que Claude pourrait produire moins d’artefacts détectables que les autres modèles.
Le taux de détection d’auto-détection suit la même tendance, indiquant que Claude crée un texte avec moins d’artefacts, ce qui le rend plus difficile à distinguer de l’écriture humaine.
Mais bien sûr, ce qui est étrange, c’est que Claude était également incapable de détecter lui-même son propre contenu original, contrairement aux deux autres modèles qui avaient un taux de réussite plus élevé.
Les chercheurs ont indiqué que l’auto-détection reste un domaine intéressant pour la poursuite des recherches et proposent que d’autres études puissent se concentrer sur des ensembles de données plus vastes avec une plus grande diversité de textes générés par l’IA, tester des modèles d’IA supplémentaires, une comparaison avec davantage de détecteurs d’IA et enfin ils ont suggéré d’étudier comment une ingénierie rapide peut influencer les niveaux de détection.
Lisez le document de recherche original et le résumé ici :
Auto-détection de contenu IA pour les grands modèles de langage basés sur des transformateurs
Image en vedette par Shutterstock/SObeR 9426
منبع: https://www.searchenginejournal.com/ai-content-detection-bard-vs-chatgpt-vs-claude/505087/

